English to SQL translation is getting better! Can you guess which of these queries to find the actor appearing in the most movies (in a fictional dataset) was written by a human, and which by machine?
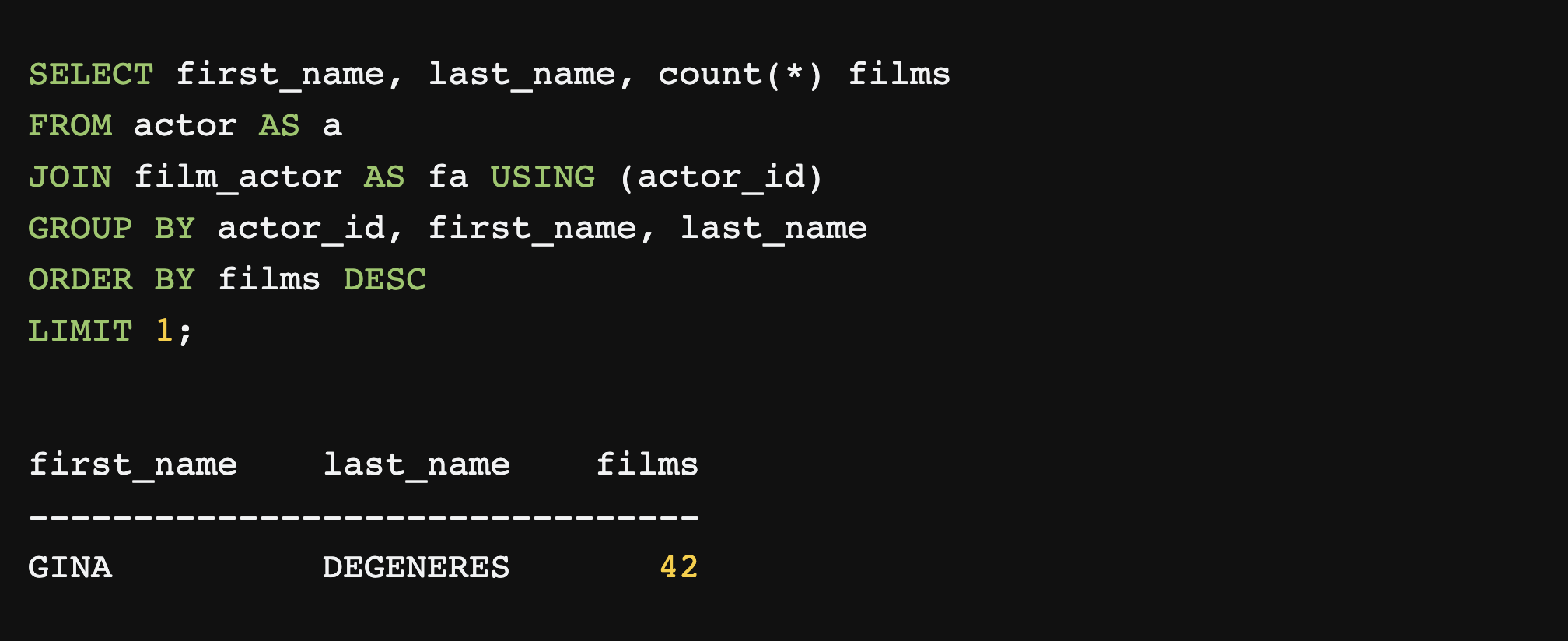
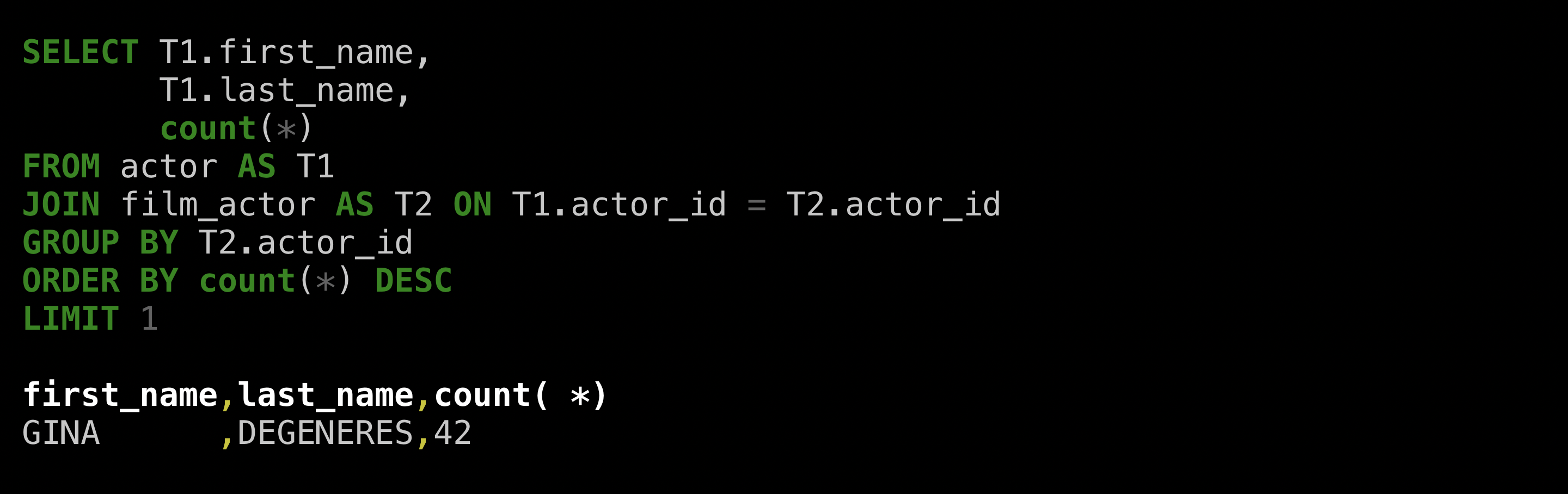
Well ok yes you probably can, but the point is they are both pretty good!
In early 2019, when I was looking for published models for text to SQL translation, I had the most joy with one called SQLova (Hacker News discussion from that time). SQLova was trained on the WikiSQL dataset, a collection of natural language questions and SQL queries for tables drawn from Wikipedia. Part of what made SQLova work well was using BERT to transform its input. BERT is a model released in 2018 for generic NLP tasks, trained on BooksCorpus and English Wikipedia, that led to a wave of state-of-the-art improvements in all sorts of language problems as people bolted it on to their models. That wave continues to this day, and BERT’s descendants get better and better.
SQLova was limited to queries on a single table, which is not the most interesting use to make of relational databases. In 2018 the Spider dataset had been released, with questions and queries involving multiple tables, so I was looking forward to models showing up trained on that. IRNet come out with a pretrained model in late 2019, and I started playing with it. It was great to see joins and more complex clauses coming into play. But a downside of work benchmarked on the Spider dataset was that the benchmark didn’t include what is called “value” prediction (such as figuring out parameters in a query), and research code developed with Spider in mind often skipped that. This makes sense from a research perspective, but generates incomplete queries.
I noticed a network called ValueNet released recently. Building on IRNet, it adds on some machinery for guessing values, and generally makes more of an effort to produce fully executable queries. I appreciate that. Let’s try it out!
As a concrete example, let’s use the Sakila database, as introduced on the jook website. This is a (fictional) database about movie rentals from physical stores back when that was a thing. It has 16 tables, with a rich relational structure:
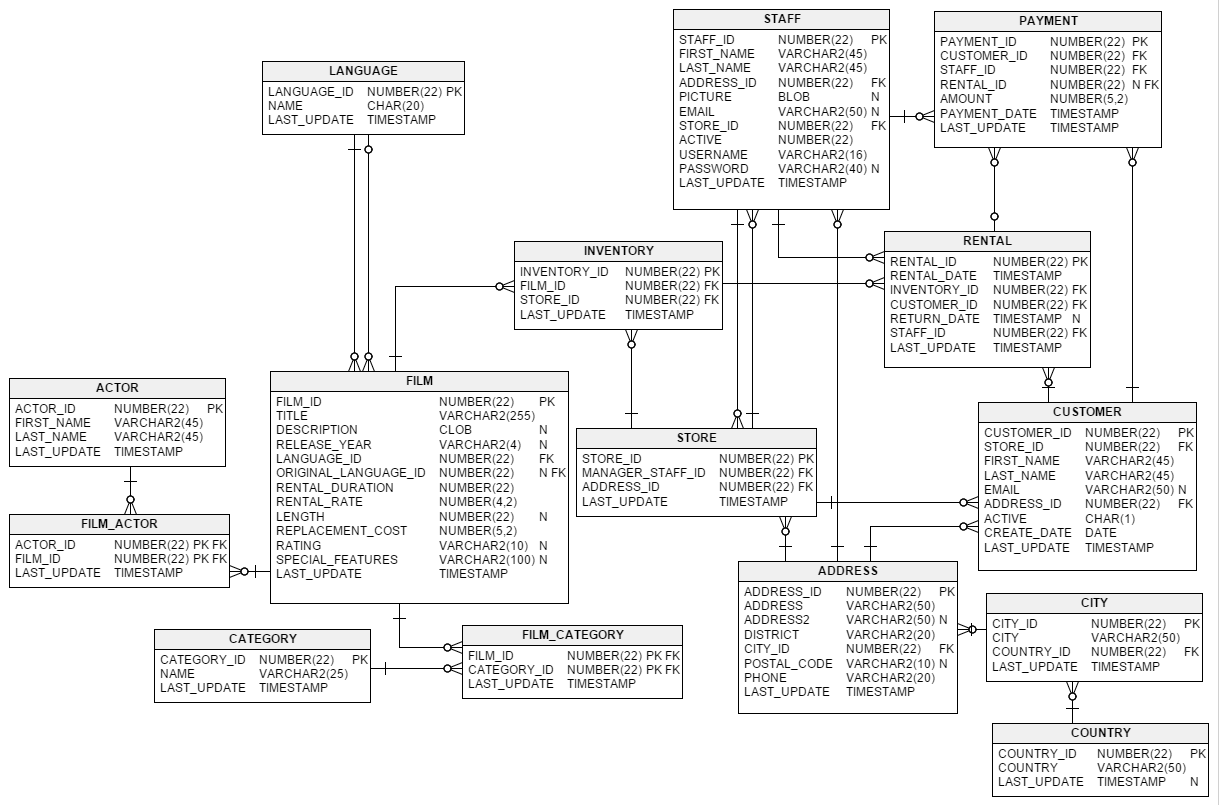
On the jook website, they give an example of a (human-written) query that “finds the actor with most films”:
Let’s see what ValueNet can do:
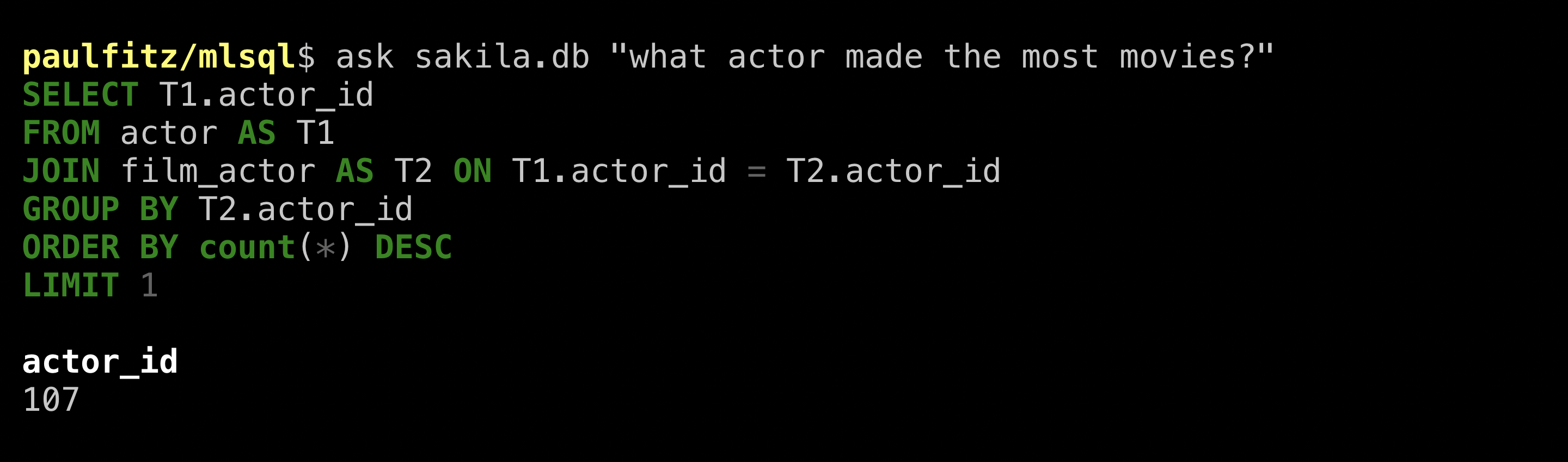
(I wrote movies rather than films because I’ve lived in the United States too long, but it works either way). The SQL looks plausible! It picked the right tables, relations, and aggregations. But the answer is just an ID. Let’s be more explicit that we want a name:
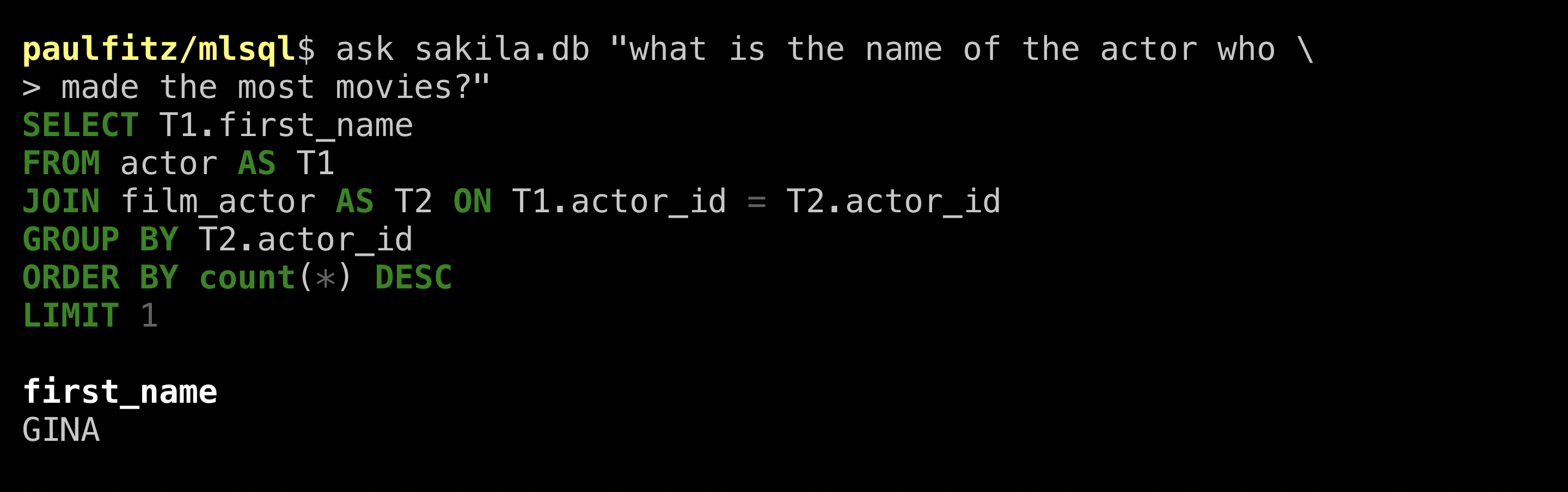
Gina! Looks like the result matches what the human got. ValueNet gave us a name, but in a begrudging way, just the first name. Let’s get more specific again and ask for a full name:
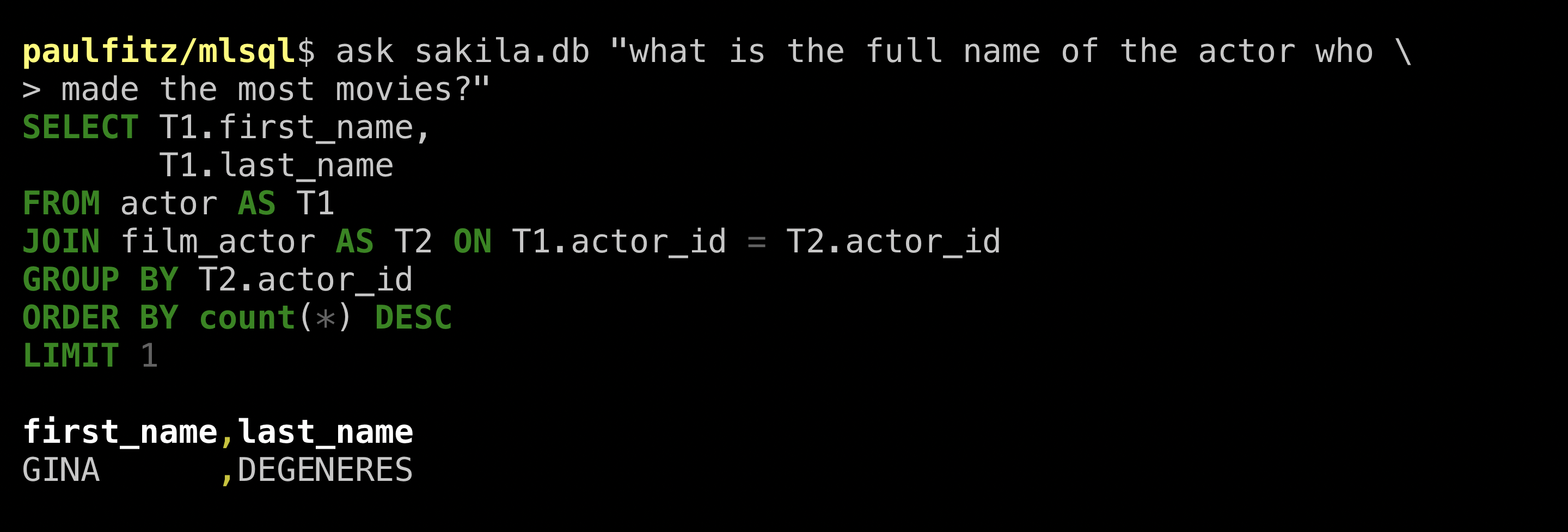
Neat, it gave us all the name parts in the table. It didn’t know how to construct a full name but who does really. To match the human query, let’s also ask how many films this Gina person acted in:
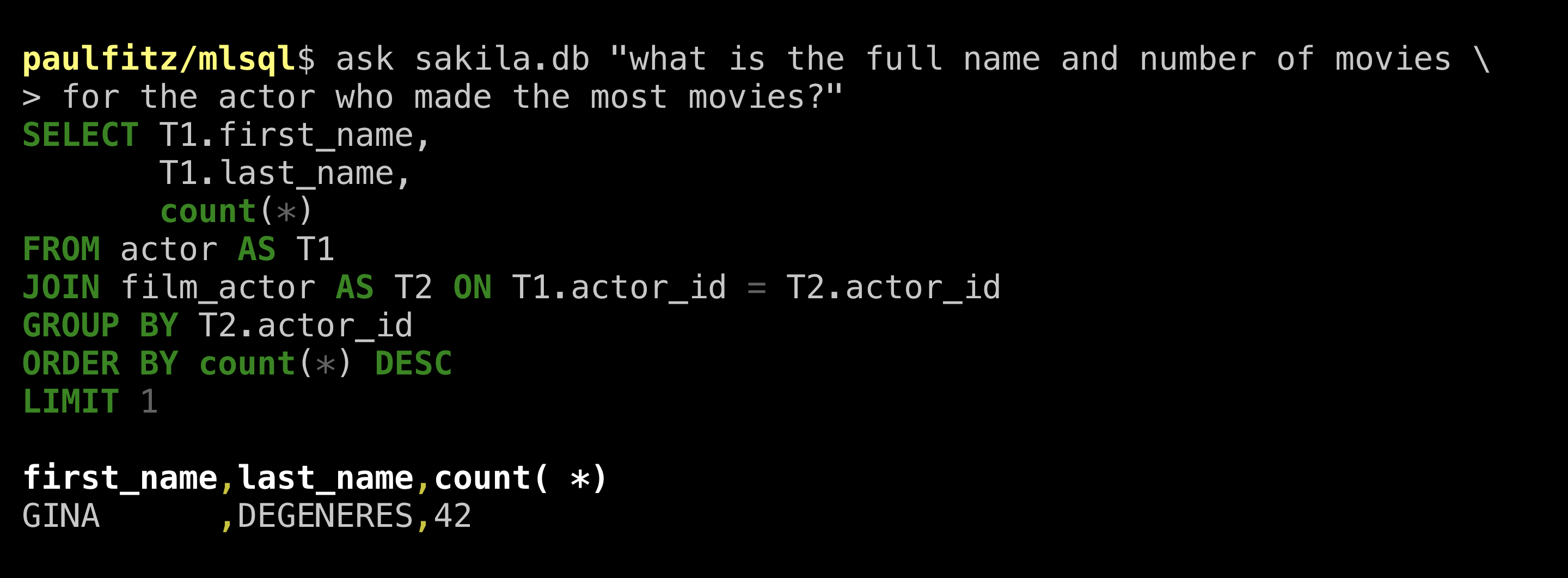
That was a pleasant experience. There was no cherry-picking here, I downloaded the database and tried it on ValueNet and this is what I got. It’d be nice if the network could better guess what full set of information is useful to give, but it was definitely helpful. Also, compared to single-table operation in Sqlova, I am excited to see the network picking good tables to look at from the soup available, and relating them appropriately.
The jook website goes on to give another example (human-written) query to “calculate the cumulative revenue of all stores”:
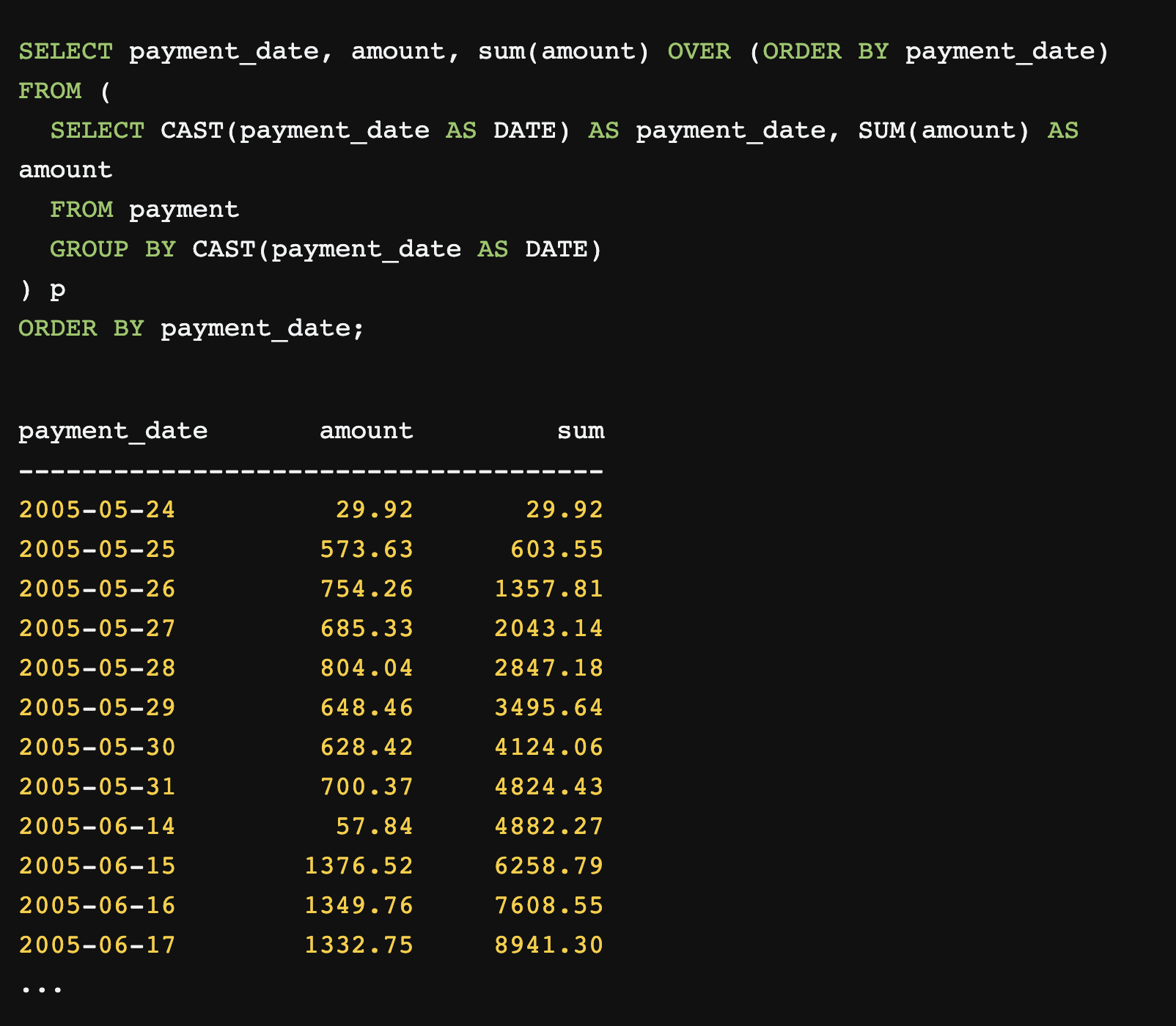
That’s a mouthful. Let’s see what ValueNet does:
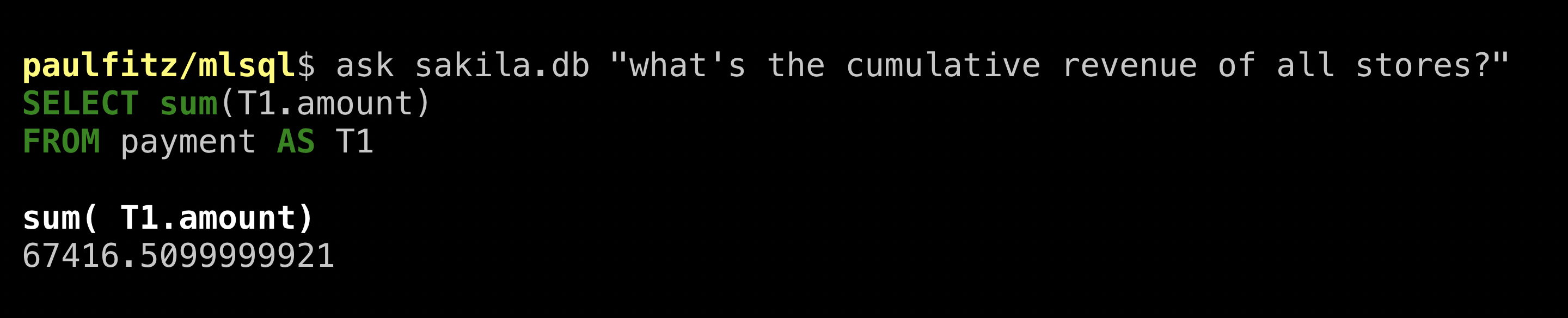
That’s not bad! It figured out the relevant tables and columns. I couldn’t nudge ValueNet to break this down by day though. Understandable, since there is nothing structured around days in the database. I’d expect the next generation of models to be able to get that kind of thing though, given that GPT-3 could no doubt write a detailed essay about it.
As a consolation prize, I asked for a break-down by movie, which I got without fuss:
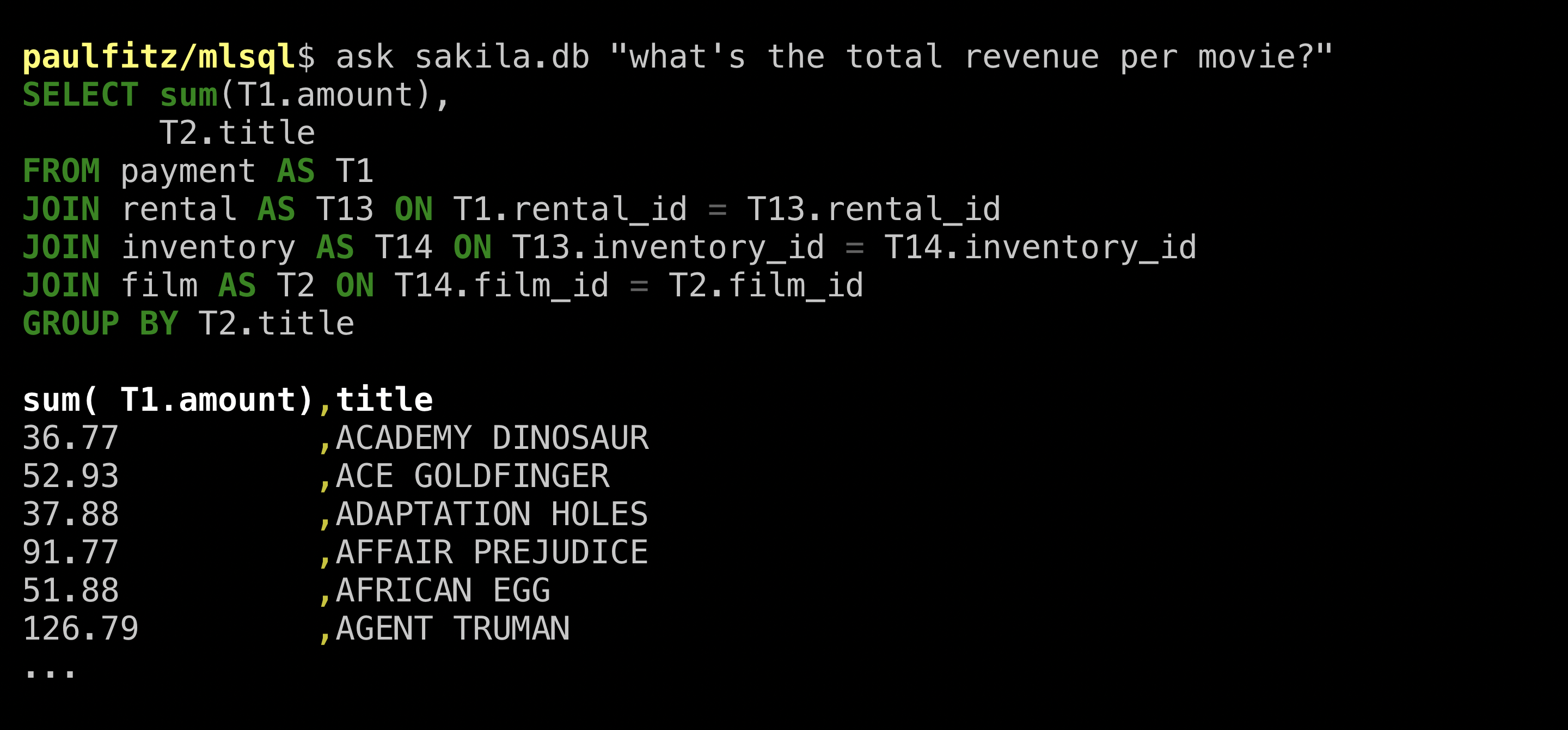
Neat! And the great thing is, you don’t need to take my word about any of this, this is not some massive network behind an invite-only API like some networks I could mention 😉. Just go to https://github.com/brunnurs/valuenet and follow their instructions.
My experience with research code in this area is that it is often difficult to run on data outside of the dataset it is benchmarked on, since the pipeline for pre-processing that data can be hard to nail down. I’ve made a docker image specifically for running ValueNet on fresh data, and without a GPU (since you don’t need it for inference really). Also, to make the whole thing self-contained, I ripped out a use of Google’s Named Entity Recognition API and replaced it with something from spacy. If you have docker, and it is configured so it can use lots of RAM (3GB or so?), then you can do:
$ wget https://paulfitz.github.io/files/sakila.db
$ docker run --name valuenet -d -p 5050:5050 paulfitz/valuenet
# wait a while
$ curl -F "sqlite=@sakila.db" -F "q=what is the title of the longest film" http://localhost:5050
# {"result":{"answer":[["CHICAGO NORTH"]],"sql":"SELECT T1.title FROM film AS T1 ORDER BY T1.length DESC LIMIT 1"},"split":"case_1db37f79-bbfe-4d70-a367-13e785f5e180"}
$ curl -F "sqlite=@sakila.db" -F "q=what is the full name of the actress whose last name is 'WITHERSPOON'" http://localhost:5050
# {"result":{"answer":[["ANGELA","WITHERSPOON"]],"sql":"SELECT T1.first_name, T1.last_name FROM actor AS T1 WHERE T1.last_name = 'WITHERSPOON'"},"split":"case_2cbddbed-2704-4037-8a4a-82e9a8a0f3a2"}There’s more information at https://github.com/paulfitz/mlsql.
How we query databases is ripe for a transformation. Companies have been developing and releasing natural language interfaces for decades. But outside of niche uses they’ve so far been more trouble than they are worth - brittle, inflexible, lacking common sense. But the field of natural language processing has evolved a lot, to the point where we now have access to representations that are far more robust, flexible, and - if not exactly having common sense - encode a lot of knowledge about relationships between currencies, names, chronology, phone numbers, movies, discounts, street names, airports, email addresses, menus, pokemon, and so on. I’m looking forward to database query engines that know know more of that!