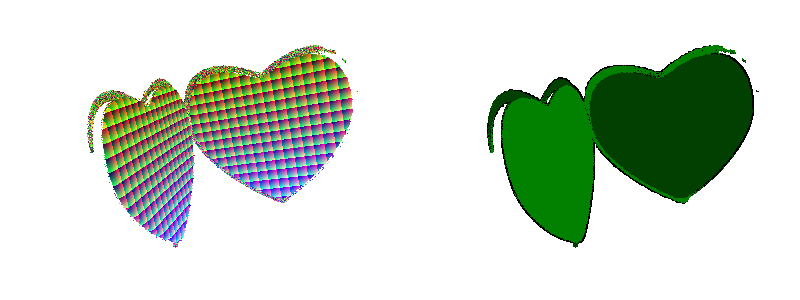Ex-goat herder. Living on a planet in space. Once and future thing.
And this is my blog. It has my name on it, and
there are dates, the blog-spoor are everywhere.
I made a heart locket animation for a Valentine’s day project years back,
and stuck a generator for it online that recently took on a life of its own
when it got adopted as a meme
I think because of a cat called Bingus??
My dumb little site had a memory leak for years, that I “solved” with
a script to restart it every night. After traffic blew up I finally
fixed this… by restarting every few minutes hash tag should be
ashamed of myself. But traffic continued to grow so I finally read the
ancient code and soon had improved server stability by orders of magnitude
by cleverly NOT IMMEDIATELY LEAKING MEMORY WITH EVERY UPLOAD.
And that was that, people were happily making their memes and my server was
quietly serving them. Then hubris hit. I said to myself, St Patrick’s day
is coming up, why not add … a green heart locket?
That will blow these memers minds. Born and raised on the red heart locket
these young folks will say “what is this” and “how can this be” and
“all we have known is wrong.” So I fired up Blender 3D and made a tasteful draft of a luminescent green heart
with shamrocks plastered all over it:
Great! To your eyes, this may look grungy and low quality. Well, it is, but
that’s not necessarily a bad thing, there’s a whole scene out there with that
aesthetic. Or at least, that’s what I use as an excuse for my many technical
and artistic deficiencies.
Next, I applied my secret sauce (carefully explained in this pdf, I’m not good at secrets) to convert the Blender design into a precompiled map
so users’ uploads can be quickly substituted in for images on surfaces without
needing to re-render. That results in a sequence of templates like this:
Along with some other images, these summarize what coordinates of the users’ inputs
to lay out, and where. Once that was all done, I went to my site, visited my
new generator, stuck in some images and text and voilà:
Irsih is a misspelling of Irish for humorous effect you see, slyly referencing
the Fnich meme
and oh nevermind. But hang on, what are the funky little white speckles in there?
Leprechaun dust
I suggested on twitter. I stared at my maps, looking for a rendering problem. Nothing.
I tried making animations in different browsers, and found them only happening in Chrome.
Betrayal! I dug in to see if there were new canvas options
I needed these days (in olden times I’d been bitten by context.imageSmoothingEnabled).
Nothing. Finally, I turned off all my browser extensions… and the problem went away.
Turning the extensions back on one by one, the speckles turned out to be from the DuckDuckGo
privacy extension. Digging into its source code, I found a
modifyPixelData reaching into the canvas and randomly twiddling least significant bits
to disrupt canvas fingerprinting.
A somewhat helpful, somewhat mischievous entity sprinkling a bit of magic grit into
my life. So yes, basically, leprechaun dust.
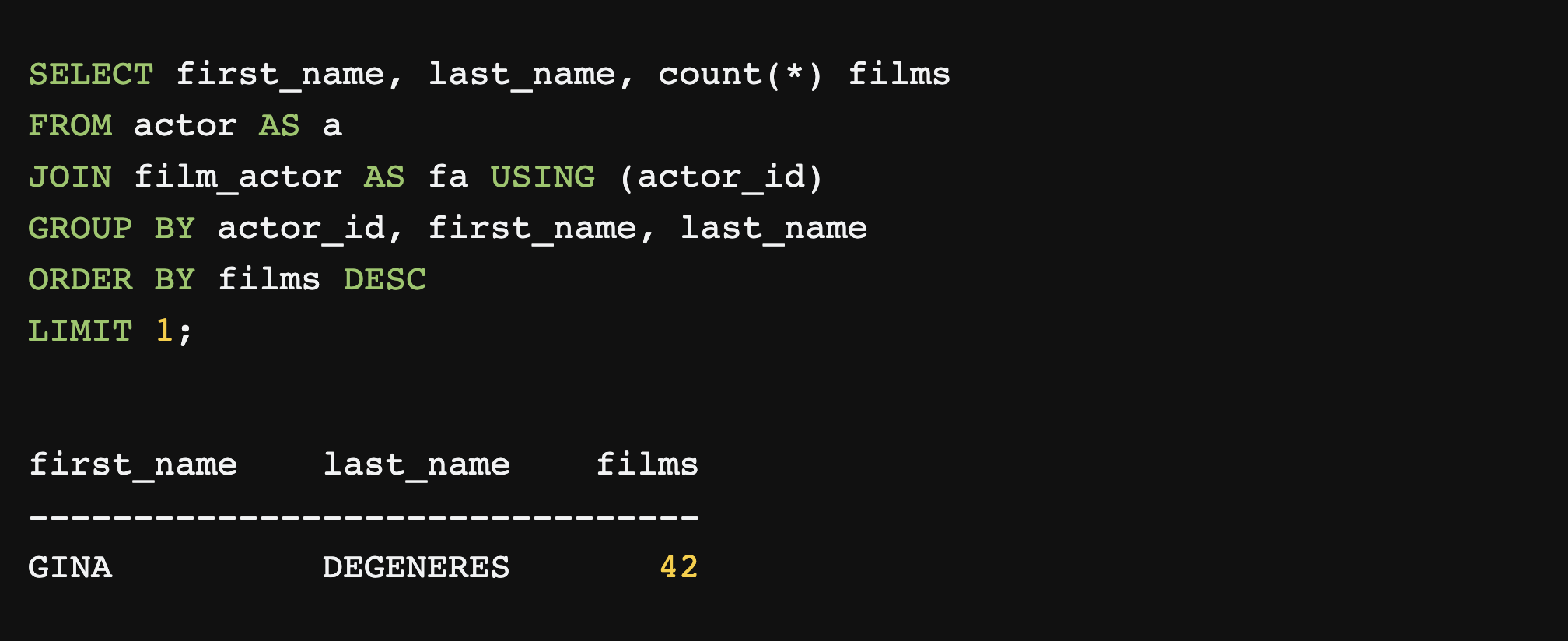
English to SQL translation is getting better! Can you guess which of
these queries to find the actor appearing in the most movies (in a fictional dataset)
was written by a human, and which by machine?
Well ok yes you probably can, but the point is they are both pretty good!
In early 2019, when I
was looking for published models for text to SQL translation, I had the most joy with one
called SQLova (Hacker News discussion from that time).
SQLova was trained on the WikiSQL dataset, a collection of natural
language questions and SQL queries for tables drawn from Wikipedia.
Part of what made SQLova work well was using BERT to transform its input.
BERT is a model released in 2018 for generic NLP tasks, trained on
BooksCorpus and English Wikipedia, that led to a wave of
state-of-the-art improvements in all sorts of language problems as
people bolted it on to their models. That wave continues to this day,
and BERT’s descendants get better and better.
SQLova was limited to queries on a single table,
which is not the most interesting use to make of relational databases.
In 2018 the Spider dataset had been released, with questions and queries
involving multiple tables, so I was looking forward to models showing up
trained on that. IRNet come out with a pretrained model in late 2019, and I started
playing with it. It was great to see joins and more complex clauses
coming into play. But a downside of work benchmarked on the Spider dataset
was that the benchmark didn’t include what is called “value” prediction
(such as figuring out parameters in a query), and research code developed with
Spider in mind often skipped that. This makes sense from a research perspective,
but generates incomplete queries.
I noticed a network called ValueNet released recently.
Building on IRNet, it adds on some machinery for guessing values, and generally makes more of an
effort to produce fully executable queries. I appreciate that. Let’s try it out!
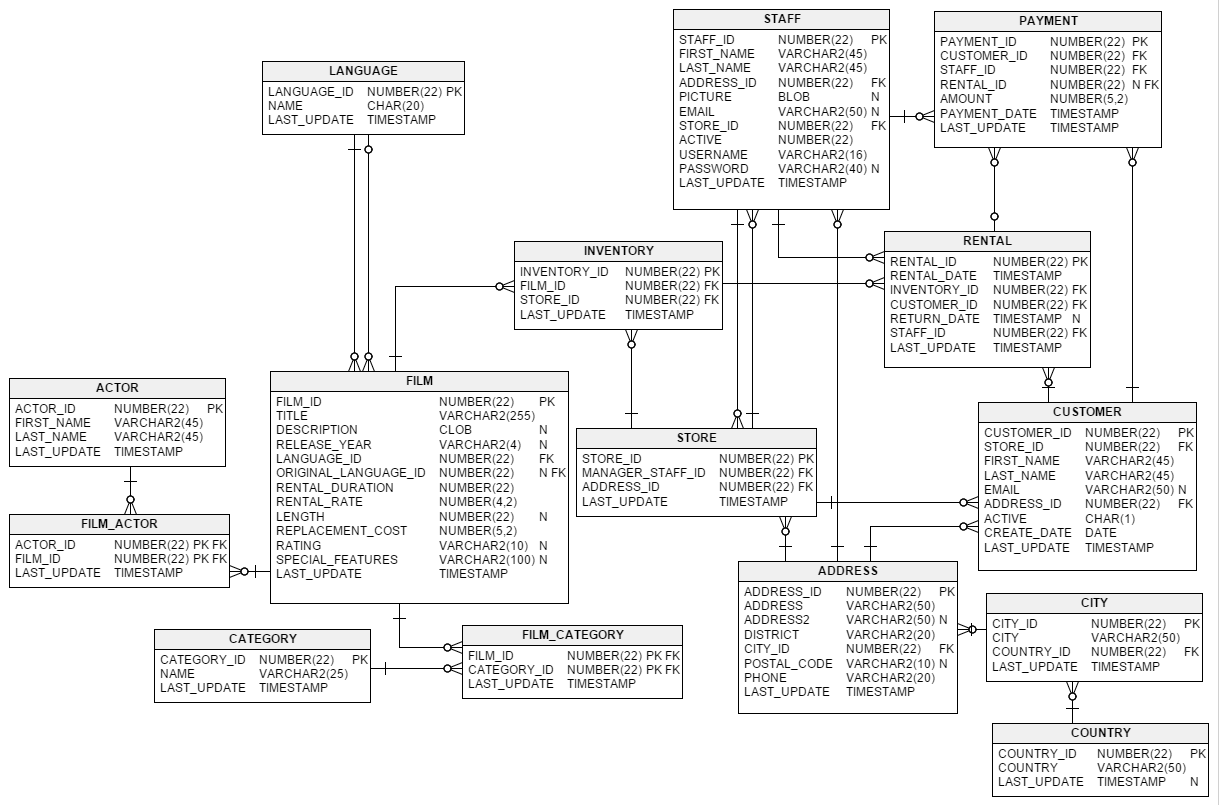
As a concrete example, let’s use the Sakila database,
as introduced on the jook website.
This is a (fictional) database about movie rentals from physical stores back
when that was a thing. It has 16 tables, with a rich relational
structure:
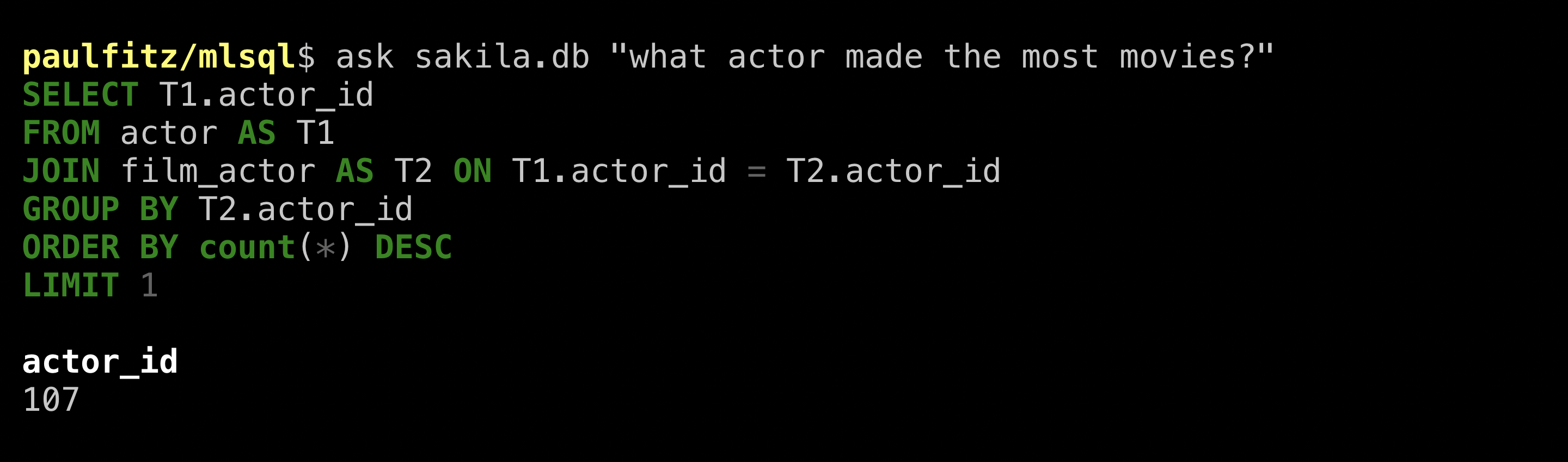
On the jook website, they give an
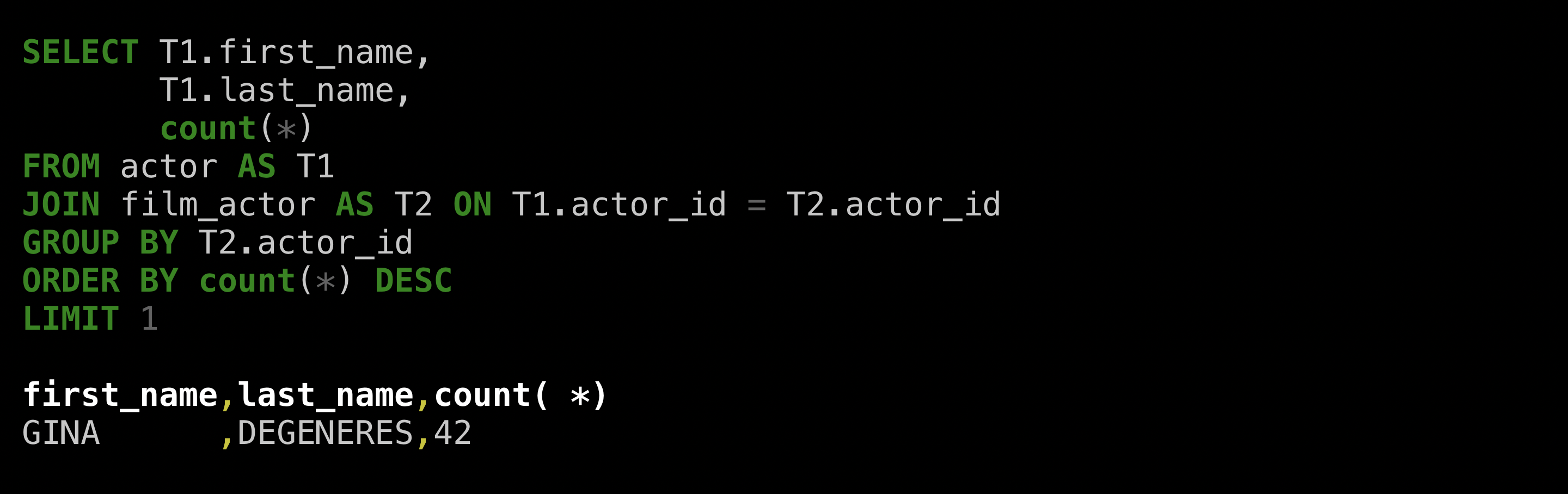
example of a (human-written) query that “finds the actor with most films”:
Let’s see what ValueNet can do:
(I wrote movies rather than films because I’ve lived in the United
States too long, but it works either way).
The SQL looks plausible! It picked the right tables, relations,
and aggregations. But the answer is just an ID. Let’s be
more explicit that we want a name:
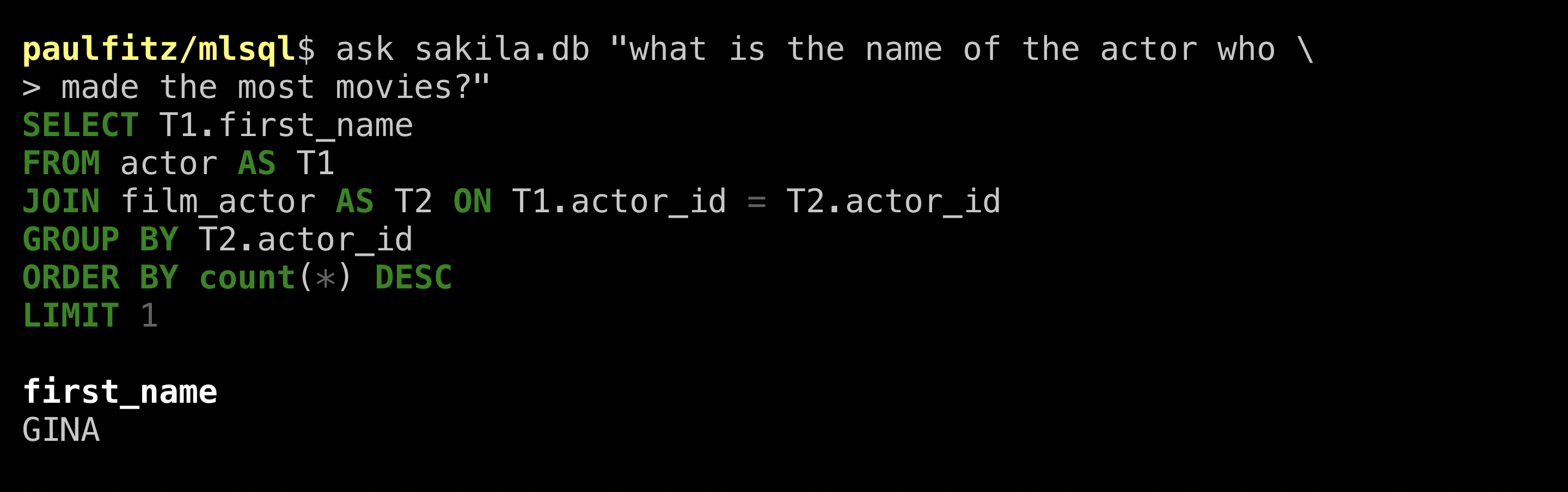
Gina! Looks like the result matches what the human got. ValueNet gave
us a name, but in a begrudging way, just the first name. Let’s get
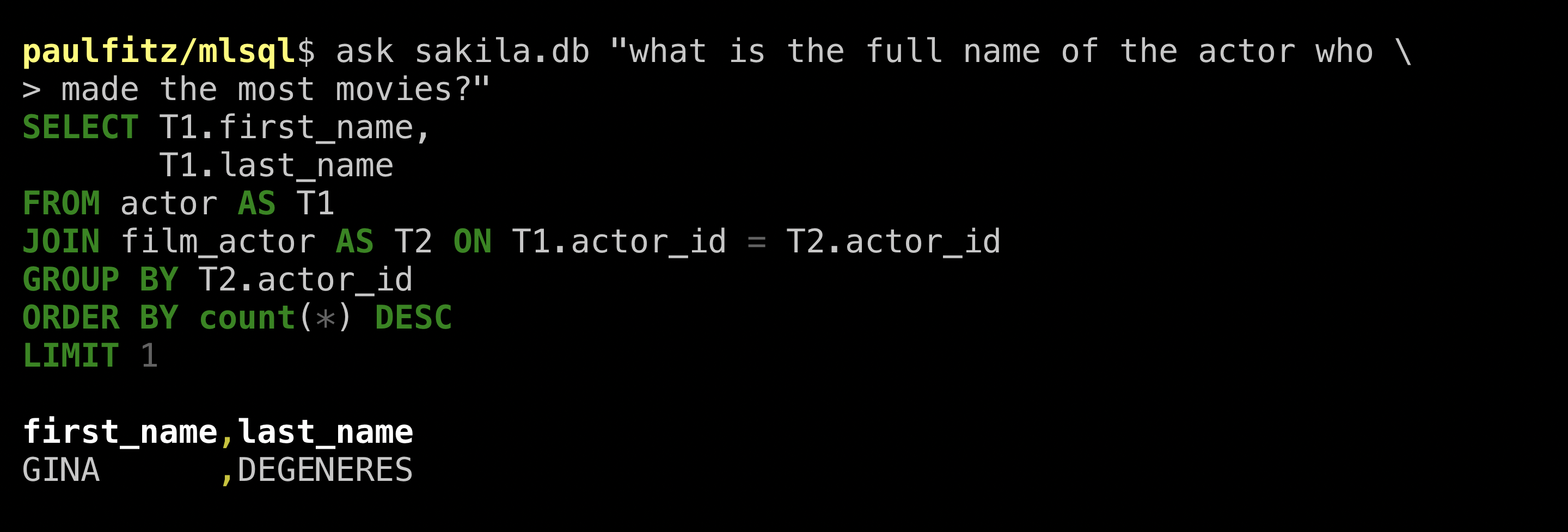
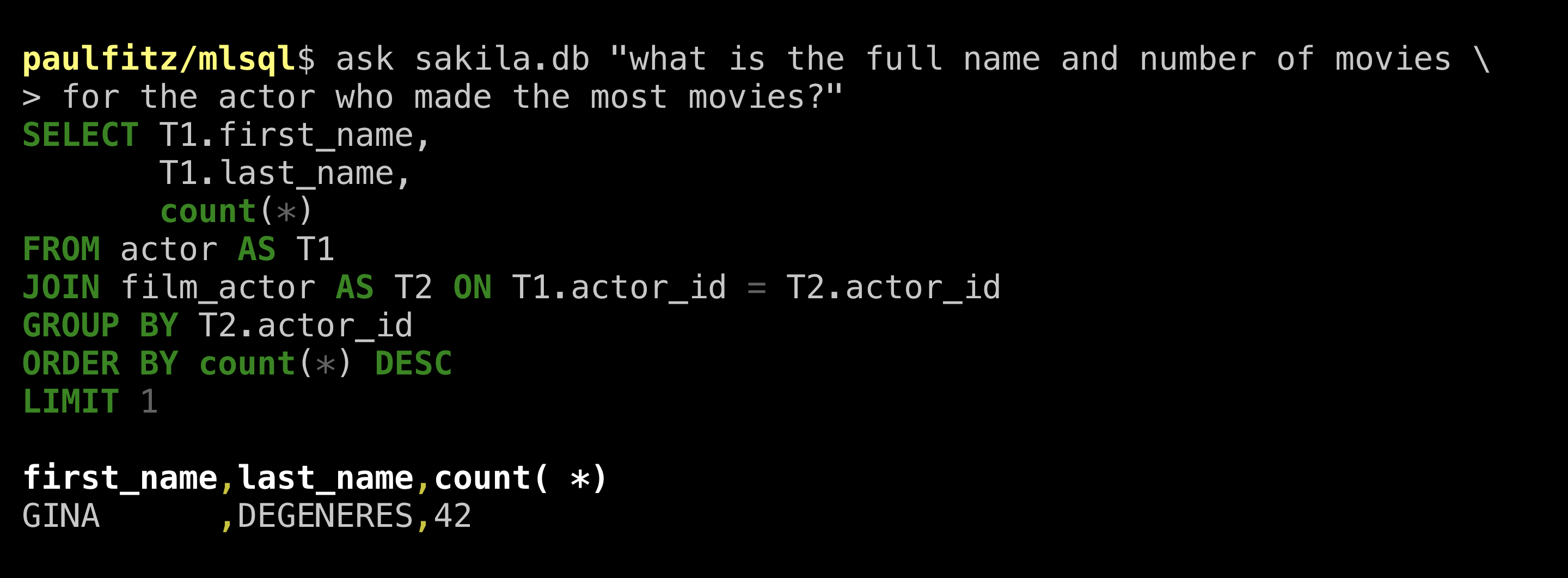
more specific again and ask for a full name:
Neat, it gave us all the name parts in the table. It didn’t know
how to construct a full name but who does really.
To match the human query, let’s also ask how many films this Gina
person acted in:
That was a pleasant experience. There was no cherry-picking here, I downloaded
the database and tried it on ValueNet and this is what I got. It’d be nice if
the network could better guess what full set of information is useful to give, but it was
definitely helpful. Also, compared to single-table operation in Sqlova, I am
excited to see the network picking good tables to look at from the soup available,
and relating them appropriately.
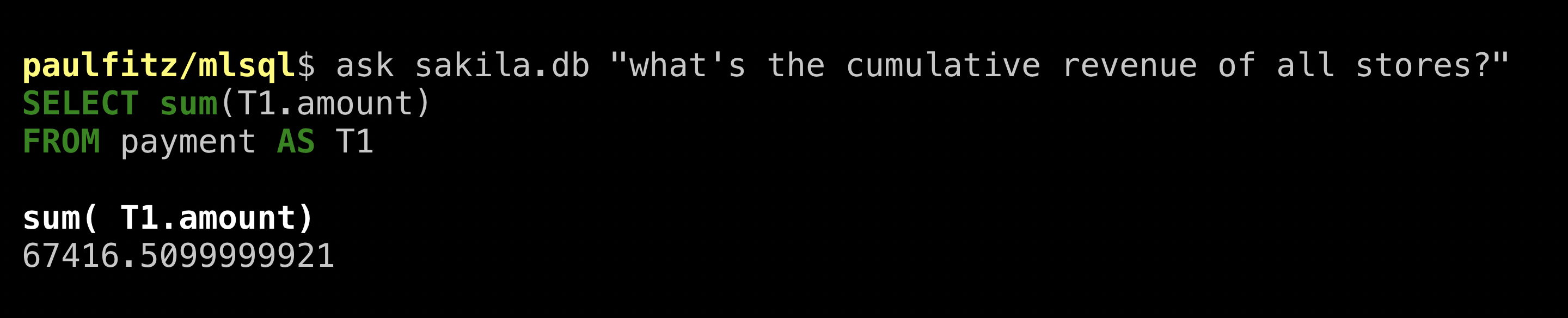
The jook website goes on to give another
example (human-written) query to “calculate the cumulative revenue of all stores”:
That’s a mouthful. Let’s see what ValueNet does:
That’s not bad! It figured out the relevant tables and columns.
I couldn’t nudge ValueNet to break this down by day though.
Understandable, since there is nothing structured around days
in the database. I’d expect the next generation of models
to be able to get that kind of thing though, given that
GPT-3 could no doubt write a detailed essay about it.
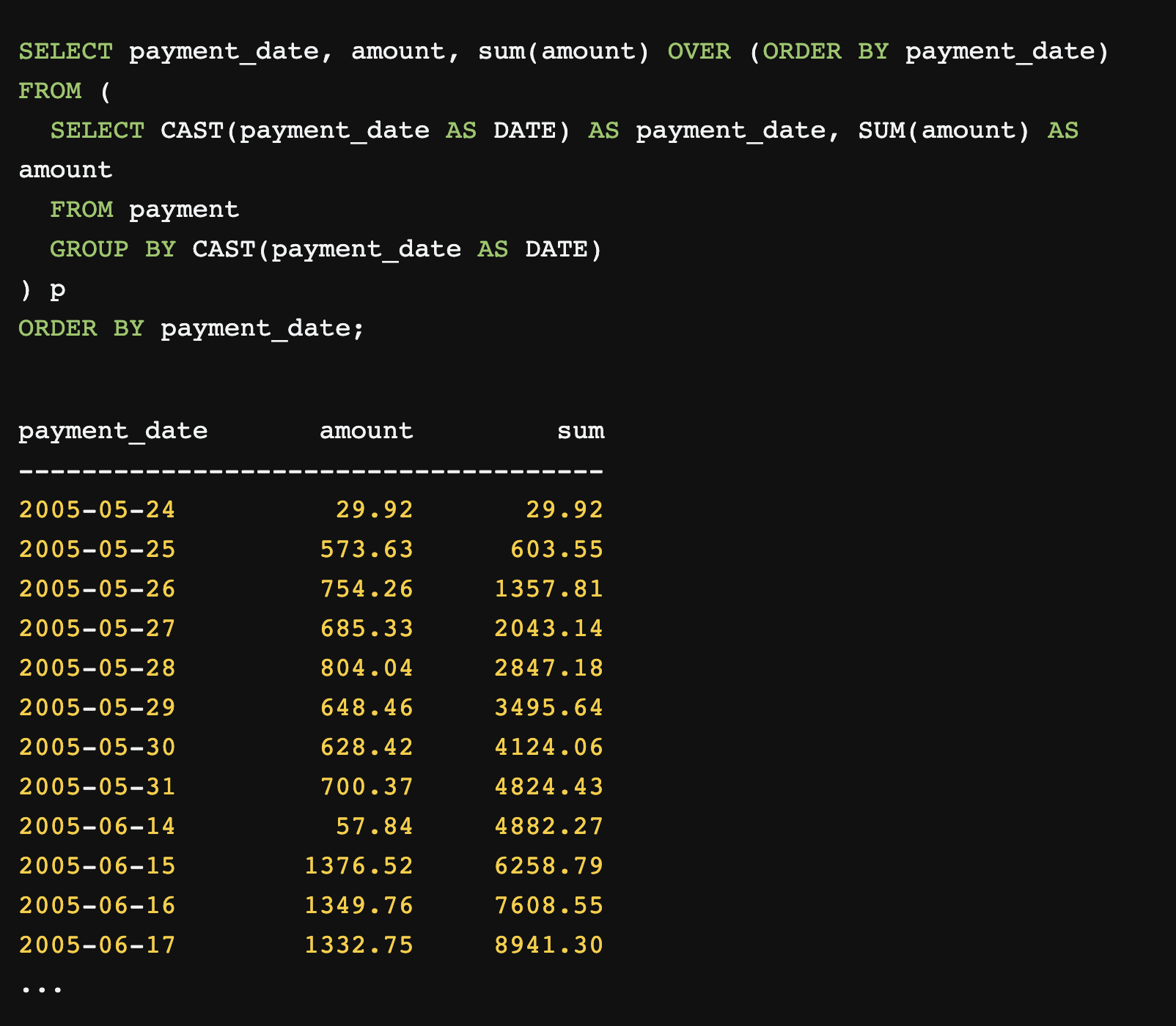
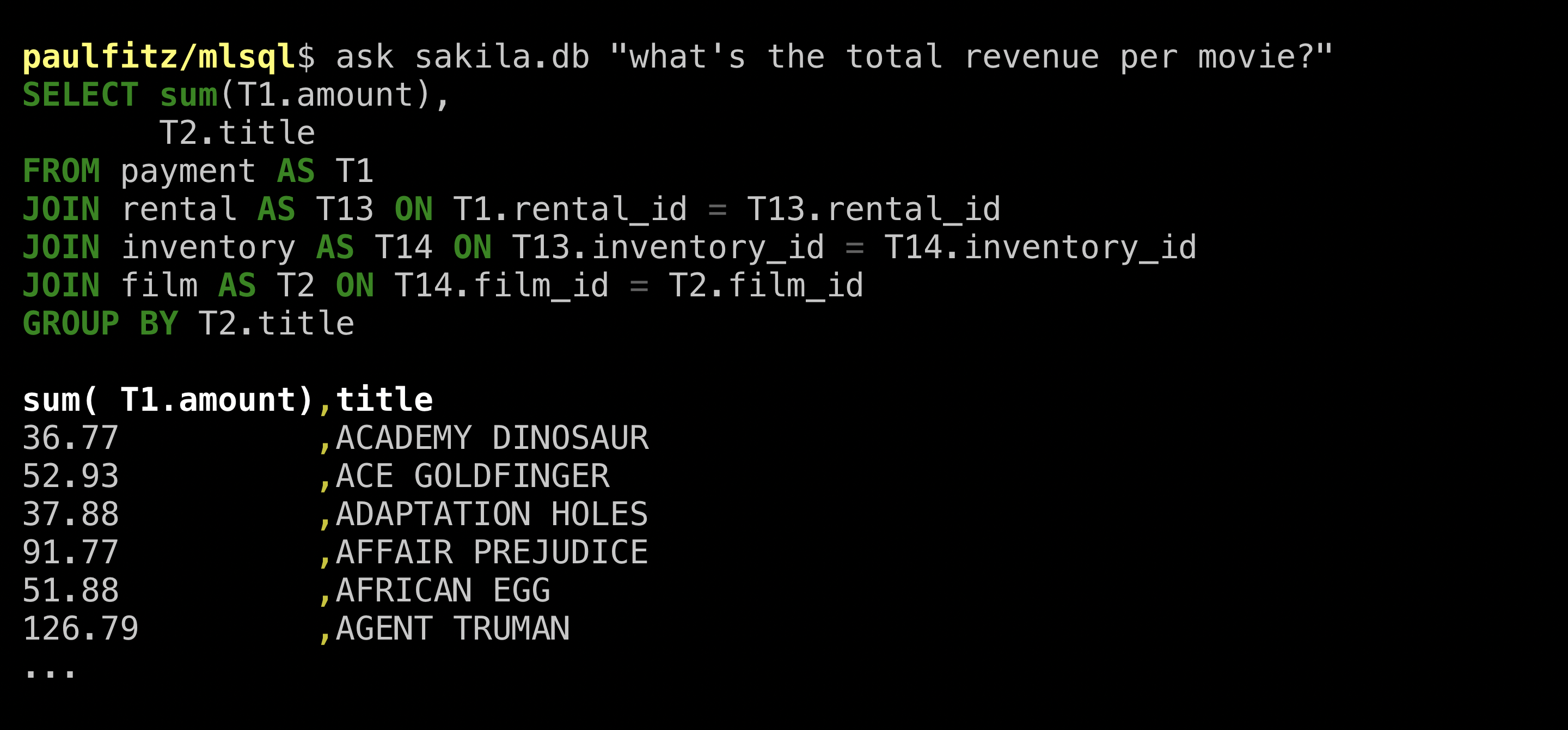
As a consolation prize, I asked for a break-down by movie, which I got
without fuss:
My experience with research code in this area is that it is often
difficult to run on data outside of the dataset it is benchmarked on,
since the pipeline for pre-processing that data can be hard to nail
down. I’ve made a docker image specifically for running ValueNet on
fresh data, and without a GPU (since you don’t need it for inference
really). Also, to make the whole thing self-contained, I ripped out a
use of Google’s Named Entity Recognition API and replaced it with
something from spacy. If you have docker, and it is configured so it
can use lots of RAM (3GB or so?), then you can do:
$ wget https://paulfitz.github.io/files/sakila.db
$ docker run --name valuenet -d-p 5050:5050 paulfitz/valuenet
# wait a while$ curl -F"sqlite=@sakila.db"-F"q=what is the title of the longest film" http://localhost:5050
# {"result":{"answer":[["CHICAGO NORTH"]],"sql":"SELECT T1.title FROM film AS T1 ORDER BY T1.length DESC LIMIT 1"},"split":"case_1db37f79-bbfe-4d70-a367-13e785f5e180"}$ curl -F"sqlite=@sakila.db"-F"q=what is the full name of the actress whose last name is 'WITHERSPOON'" http://localhost:5050
# {"result":{"answer":[["ANGELA","WITHERSPOON"]],"sql":"SELECT T1.first_name, T1.last_name FROM actor AS T1 WHERE T1.last_name = 'WITHERSPOON'"},"split":"case_2cbddbed-2704-4037-8a4a-82e9a8a0f3a2"}
How we query databases is ripe for a transformation. Companies have
been developing and releasing natural language interfaces for decades.
But outside of niche uses they’ve so far been more trouble than they
are worth - brittle, inflexible, lacking common sense.
But the field of natural language processing has evolved a lot, to the
point where we now have access to representations that are far more
robust, flexible, and - if not exactly having common sense - encode a
lot of knowledge about relationships between currencies, names,
chronology, phone numbers, movies, discounts, street names, airports,
email addresses, menus, pokemon, and so on.
I’m looking forward to database query engines that know know more of that!
When doing spreadsheet work, I like Grist
(disclaimer, I work at the company that makes it), because it lets me
use python formulas. Once I
know how to access cells and tables, I don’t have to remember weird
spreadsheet-specific commands - I can just use python list
comprehensions.
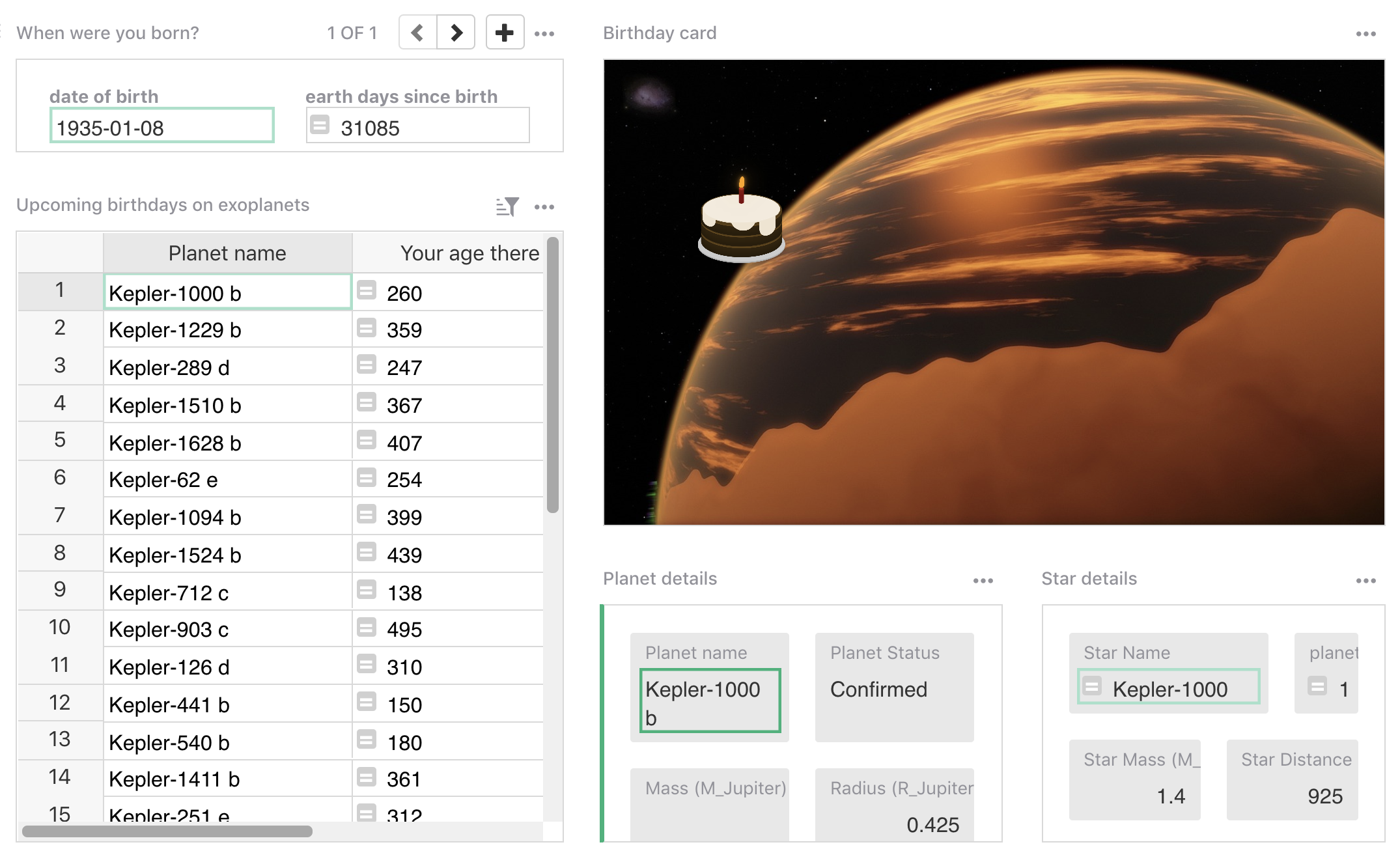
For example, when I wanted to wish someone a happy birthday every day
for a week, it was super easy to import the latest exoplanet data and
do some orbital math in python to see which exoplanets are back in
about the same point in their orbit as they were when that special
someone was born.
It is a simple difference but a real pleasure.
By the way no, I wasn’t born in January 8, 1935, that was
someone else.
Venture-backed start-ups and public companies get a lot of attention.
They are the peacocks and elephants of the business ecosystem.
But what are the earthworms, the field-mice,
the platypuses? There are lot of interesting businesses
out there built with very different DNA.
One of them is the Data Commons Co-op,
and more of them are members of members of that co-op. Let me break
that down.
In the eyes of the law, the DCC is a Mercantile Cooperative, incorporated
in the Commonwealth of Massachusetts (opencorporates listing). It is organized as a shared services cooperative,
where members band together to lower operating costs for services that
they all need.
The Data Commons Co-op greases the flow of data between communities
in the cooperative, solidarity, new, call-it-what-you-will
economy. The co-op not only serves these communities, it is owned by
them.
Some of the members of the DCC are individuals such as academics,
but most are umbrella or support organizations –
nationwide federations
(e.g. the US Federation of Worker Co-ops),
state-level development organizations
(e.g. Cooperative Maine),
sector-level organizations
(e.g. the Cooperative Grocer Network),
and others.
So the members of the members of the co-op are thousands of fun
places like Local Sprouts, a worker-owned café and bakery
in downtown Portland Maine.
Financially, the Data Commons Co-op is engineered by its
bylaws to operate at cost.
It has a tiny budget, funded mostly
from membership dues. In 2017 it has no staff; most of the work today
is done by a board of directors, and occasional volunteers (I’m one).
There are always new and interesting people joining and leaving.
The main niche the co-op has found for itself is backing member-created
maps and directories. For example, the U.S. Solidarity Economy
Mapping Platform, solidarityeconomy.us,
builds on DCC software, and relies on DCC hosting. The co-op is becoming
a pool for census projects and member directories, reducing costs and
clearing away grit. It is a place where people go
to ask questions about the weird and wonderful organizations shaping
the cooperative/solidarity/new economy.
The DCC can’t answer a lot of those questions yet.
The find.coop directory was an attempt
by the co-op to make a “stone soup” map of all the organizations
it (and its members) knew about. The idea was that members would
chip lists of organizations they could vouch for, and the directory
would pull them all together.
What we’ve learned since making this prototype:
Most fresh, reliable information comes from organizations making
a determined survey or census of a part of the economy they
care about and have expertise in.
Drive-by individual contributions can happen, but are not
a great starting point for the DCC at this stage of its
development. Getting moderation and trust right at this
level of granularity seems expensive.
I’m now working on a new map (codenamed “stone souper”) incorporating
these lessons. The main change is an extreme streamlining of
how member-contributed listings are added.
Every listing in the database can be tracked to a contributing
member.
All listings from a given contributor can be removed or
replaced without trouble.
That means contributors will feel less pressure to have their
listings in perfect shape before chipping in, and can be
secure in knowing they can pull the listings if something
unexpected comes up.
The main technical change in the map has been to move more intelligence
into search and display, so that related listings are discovered,
grouped, and summarized appropriately.
With the existing directory, it was practically impossible with
the volunteer time available to import data that overlapped
with existing listings, including previous versions of the same
listings (d’oh!)
Excited to be finally building this, and thanks to all the DCC
members who’ve been so patient and helpful along the way!
Often enough, I want to make a small change in a SQL database.
Reset a user. Delete a row in a request tracker. And so on.
In code, using my favorite ORM, I’ve become used to not worrying
about which flavor of SQL database I’m working with. I’d like
the same freedom on the command line. So I made catsql
for cating slices of databases, and
visql /
emacsql /
nanosql for making quick edits.
Just specify a table and any filters you want to apply, and the table
will show up in vi (or emacs, or nano) in csv format.
Any edits you make will be applied back to the original source.
This works fine on large tables. Just specify a filter for the part
of the table you want to work on. Only that part will be requested and shown.
Under the hood, daff is used to figure out what
changes you want and how to apply them with a SQL update.
Imagine a buddy asks you to write a program to detect a simple
visual pattern in a video stream.
They plan to print out the pattern, hang it on the wall in a gallery,
then replace it digitally with artworks to see how they’ll look in the
space.
“Sure,” you say. This is a totally doable problem, since the pattern
is so distinctive.
In classic computer vision, a young researcher’s mind would swiftly turn
to edge
detection, hough transforms, morphological operations and the like.
You’d take a few example pictures, start coding something, tweak it,
and eventually get something that works more or less on those pictures.
Then you’d take a few more and realize it didn’t generalize very well.
You’d agonize over the effects of bad lighting, occlusion, scale,
perspective, and so on, until finally running out of time
and just telling your buddy all the limitations of your detector.
And sometimes that would be OK, sometimes not.
Things are different now. Here’s how I’d tackle this problem today,
with convnets.
First question: can I get labelled data?
This means, can I get examples of inputs and the corresponding desired
outputs? In large quantities? Convnets are thirsty for training data.
If I can get enough
examples, they stand a good shot at learning what I
used to program, and better.
I can certainly take pictures and videos of me walking around putting
this pattern in different places, but I’d have to label where the
pattern is in each frame, which would be a pain. I might be able to
do a dozen or so examples, but not thousands or millions. That’s not
something I’d do for this alleged “buddy.” You’d have to pay me, and
even then I’d just take your money and pay someone else to do it.
Second question: can I generate labelled data?
Can I write a program to generate examples of the pattern in different
scenes? Sure, that is easy enough.
Relevance is the snag here. Say I write a quick program to “photoshop”
the pattern in anywhere and everywhere over a large set of scenes.
The distribution of such
pictures will in general be sampled from a very different space to real
pictures. So we’ll be teaching the network one thing in class and then
giving it a final exam on something entirely different.
There are a few cases where this can work out anyway. If we can make
the example space we select from varied enough that, along the dimensions
relevant to the problem, the real distribution is contained within it,
then we can win.
Sounds like a real stretch, but it’ll save hand-labelling data so let’s
just go for it! For this problem, we might generate input/output pairs like this:
Here’s how these particular works of art were created:
Grab a few million random images from anywhere to use as backgrounds.
This is a crude simulation of different scenes.
In fact I got really lazy here and just used pictures of dogs and cats
I happened to have lying around. I should have included more variety.
pixplz is handy for this.
Shade the pattern with random gradients.
This is a crude simulation of lighting effects.
Overlay the pattern on a background, with a random affine transformation.
This is a crude simulation of perspective.
Save a “mask” verson that is all black everywhere but where we just put
the pattern. This is the label we need for training.
Draw random blobs here and there across the image.
This is a crude simulation of occlusion.
Overlay another random image on the result so far, with a random level
of transparency. This is a crude simulation of reflections, shadows,
more lighting effects.
Distort the image (and, in lockstep, the mask) randomly.
This is a crude simulation of camera projection effects.
Apply a random directional blur to the image.
This is a crude simulation of motion blur.
Sometimes, just leave the pattern out of all this, and leave the mask
empty, if you want to let the network know the pattern may not
always be present.
Randomize the overall lighting.
The precise details aren’t important,
the key is to leave nothing reliable except the pattern you want learned.
To classic computer vision eyes, this all looks crazy. There’s occlusion!
Sometimes the pattern is only partially in view! Sometimes its edges are
all smeared out! Relax about that.
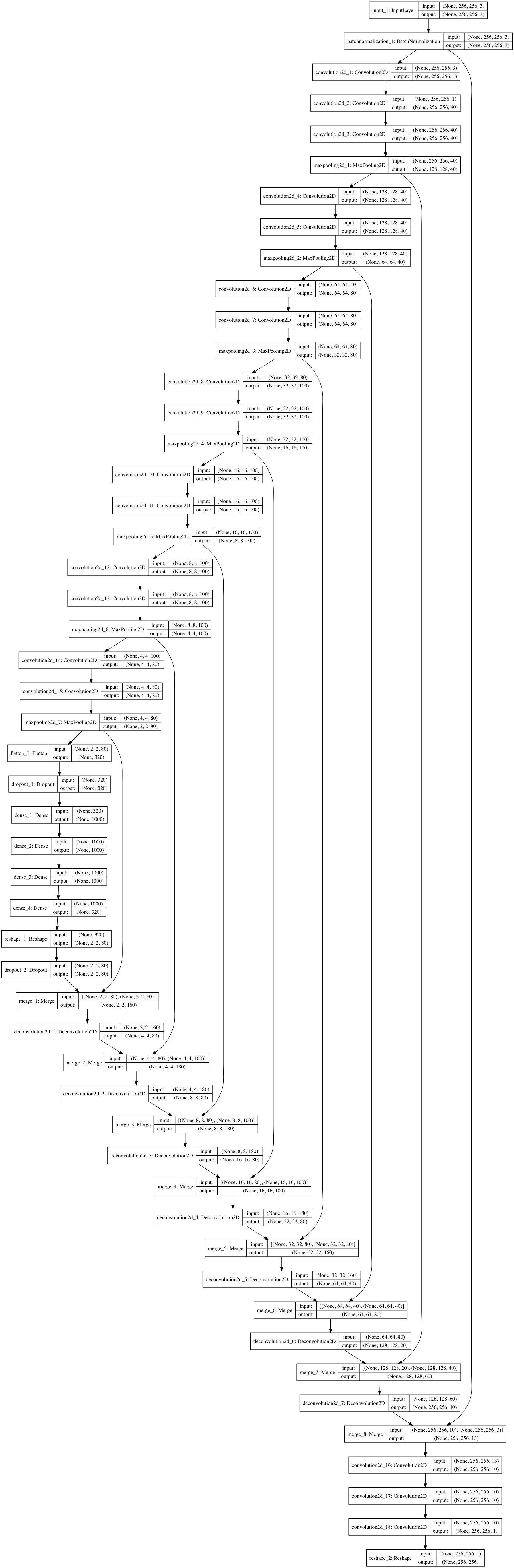
Here’s a hacked together network that should be able to do this. Let’s
assume we get images at 256x256 resolution for now.
A summary:
Take in the image, 256x256x3.
Batch normalize it - because life is too short to be fiddling around with
mean image subtraction.
Reduce it to grayscale. This is me choosing not to let the network use
color in its decisions, mainly so that I don’t have to worry too much
about second-guessing what it might pick up on.
Apply a series of 2D convolutions and downsampling via max-pooling.
This is pretty much what a simple classification network would do.
I don’t try anything clever here, and the filter counts are quite
random.
Once we’re down at low resolution, go fully connected for a layer or
two, again just like a classification network. At this point we’ve
distilled down our qualitative analysis of the image, at coarse spatial
resolution.
Now we start upsampling, to get back towards a mask image of the
same resolution as our input.
Each time we upsample we apply some 2D convolutions and blend in data from
filters at the same scale during downsampling. This is a neat trick used
in some segmentation networks that lets you successively refine a segmentation
using a blend of lower resolution context with higher resolution feature maps.
(Random example: https://arxiv.org/abs/1703.00551).
Tada! We’re done. All we need now is to pick approximately 4 million
parameters to realize all those filters.
That’s just a call to model.fit or the equivalent in your
favorite deep learning framework, and a very very long cup of coffee while training
runs. In the end you get a network that can do this on freshly generated images
it has never seen:
I switched to a different set of backgrounds for testing. Not perfect by
any means, I didn’t spend much time tweaking, but already to classical eyes
this is clearly a different kind of beast - no sweat about the pattern being
out of view, partial occlusion also no biggie, etc.
Now the big question - does it generalize? Time to take some pictures
of the pattern, first on my screen, and then a print-out when I finally
walked all the way upstairs to dust off the printer
and bring the pattern to life:
Yay! That’s way better than I’d have done by hand. Not perfect but
pretty magical and definitely a handy tool! Easy to clean up to do
the job at hand.
One very easy way to improve this a lot would be to work at higher resolutions
than 256x256 :-)
So last month an idea surfaced from @j4mie
for an alternative data format: poop separated values (PSV). Here’s the
complete spec.
At first, I laughed. Then, maybe I cried a little – 2016 went in a
kind of 💩y direction at the end there.
Finally I started thinking. I realized that PSV is a brilliant idea,
and here’s why.
What we’re talking about here is the :poop: emoji, standarized as
U+1F4A9 PILE OF POO
in Unicode 6.0.
Look at that unicode for a minute: U+1F4A9. That’s a big number.
That’s outside the Basic Multilingual Planes my friends, and into
the Astral Planes of
the unicode standard. You have to have your act together to deal with this.
For example, Mathias Bynens covers all the muddles javascript gets into with poop in
Javascript has a Unicode Problem.
This is not the 128-odd ASCII characters your grandmother grew up with.
So isn’t that an argument not to use an astral symbol as a separator?
Let’s reflect on the failings of CSV. Jesse
Donat has a great list in a piece called
Falsehoods-Programmers-Believe-About-CSVs,
mirroring similiar lists about names,
geography and so on.
The first 8 falsehoods are all encoding related. With CSV, if your data is a table
of numbers, you don’t really have to think about encoding at all. That’s nice
right up until
the moment a non-ASCII character sneaks in there it all goes pear shaped.
But if we lead with a mandatory poop symbol, from an astral plane no less,
no-one is going to be able to punt on the encoding issue. You have
to get it right up front.
The logical conclusion of this idea would be to borrow a string
like Iñtërnâtiônàlizætiøn☃💩
from unit tests and use that as the delimiter. But 💩 alone gets us a good way there,
and looks cleaner. Err.
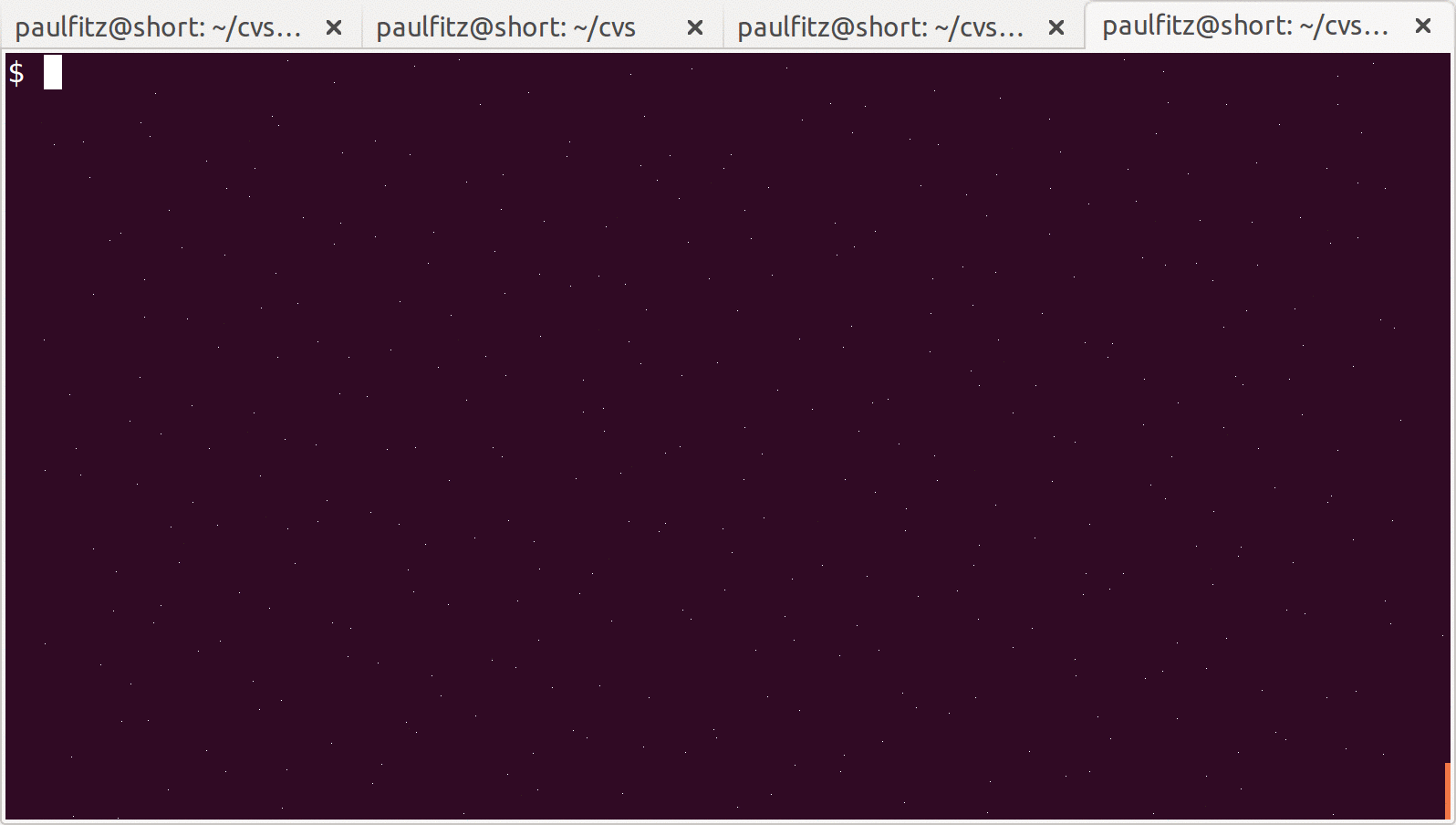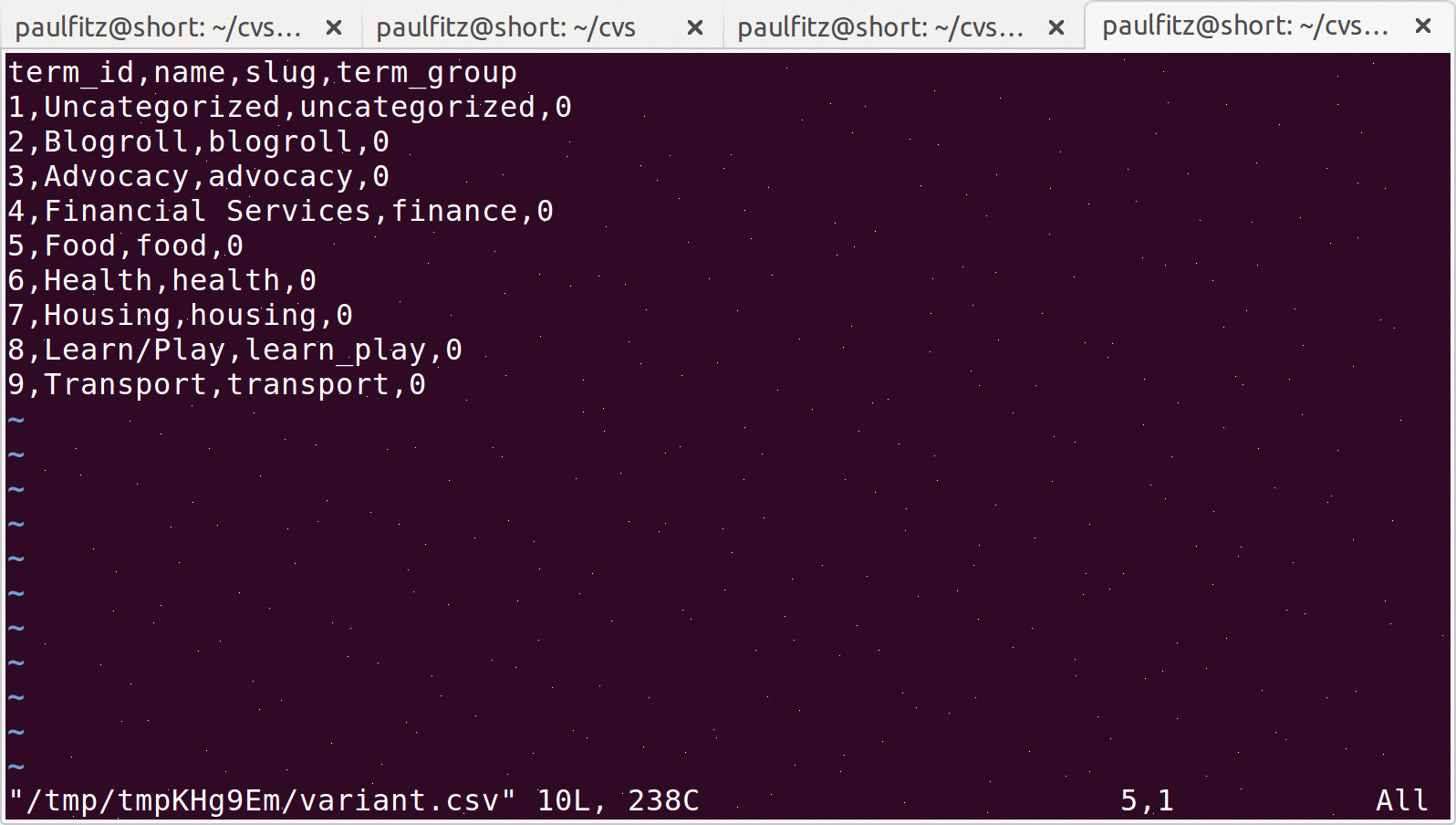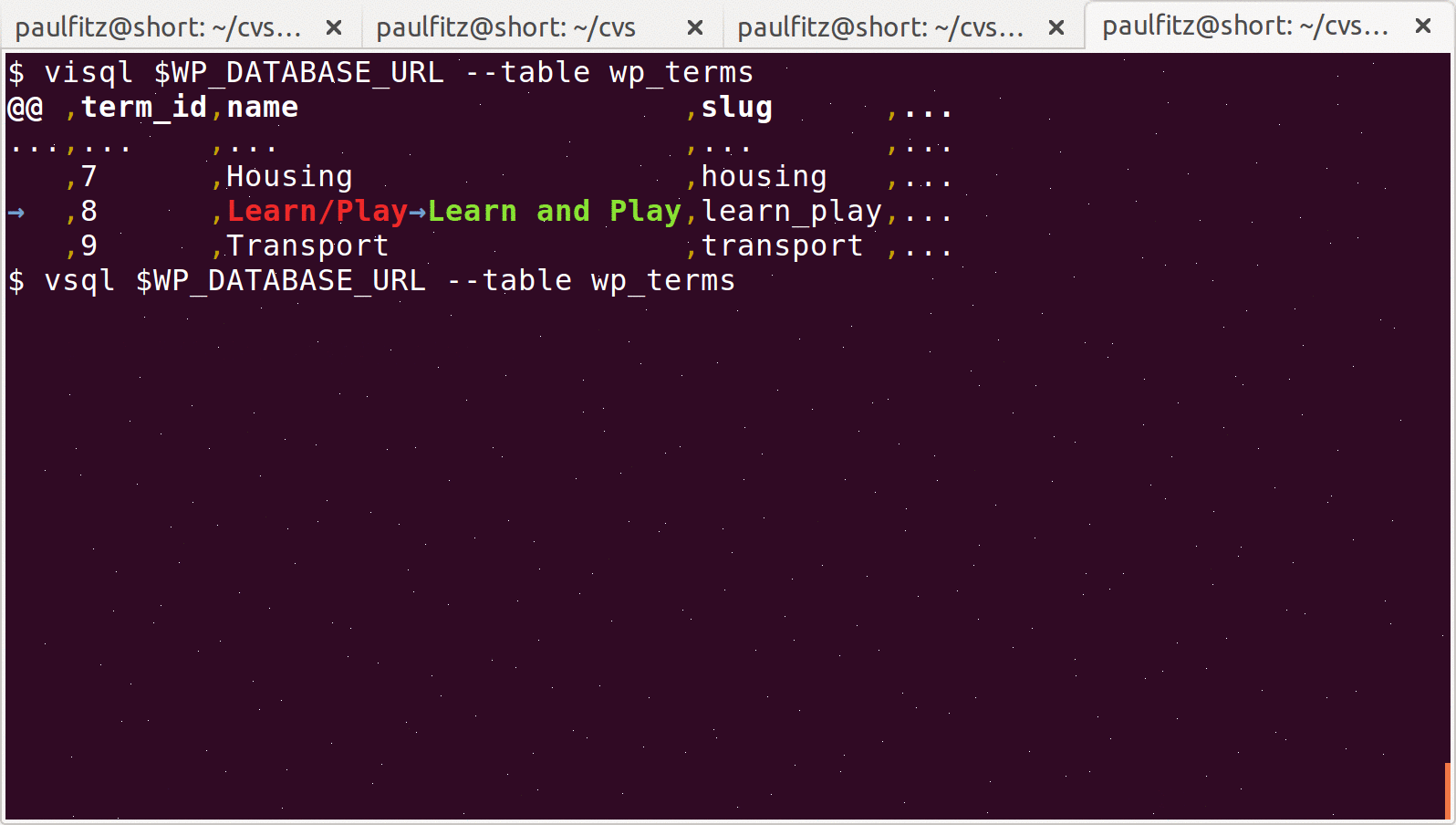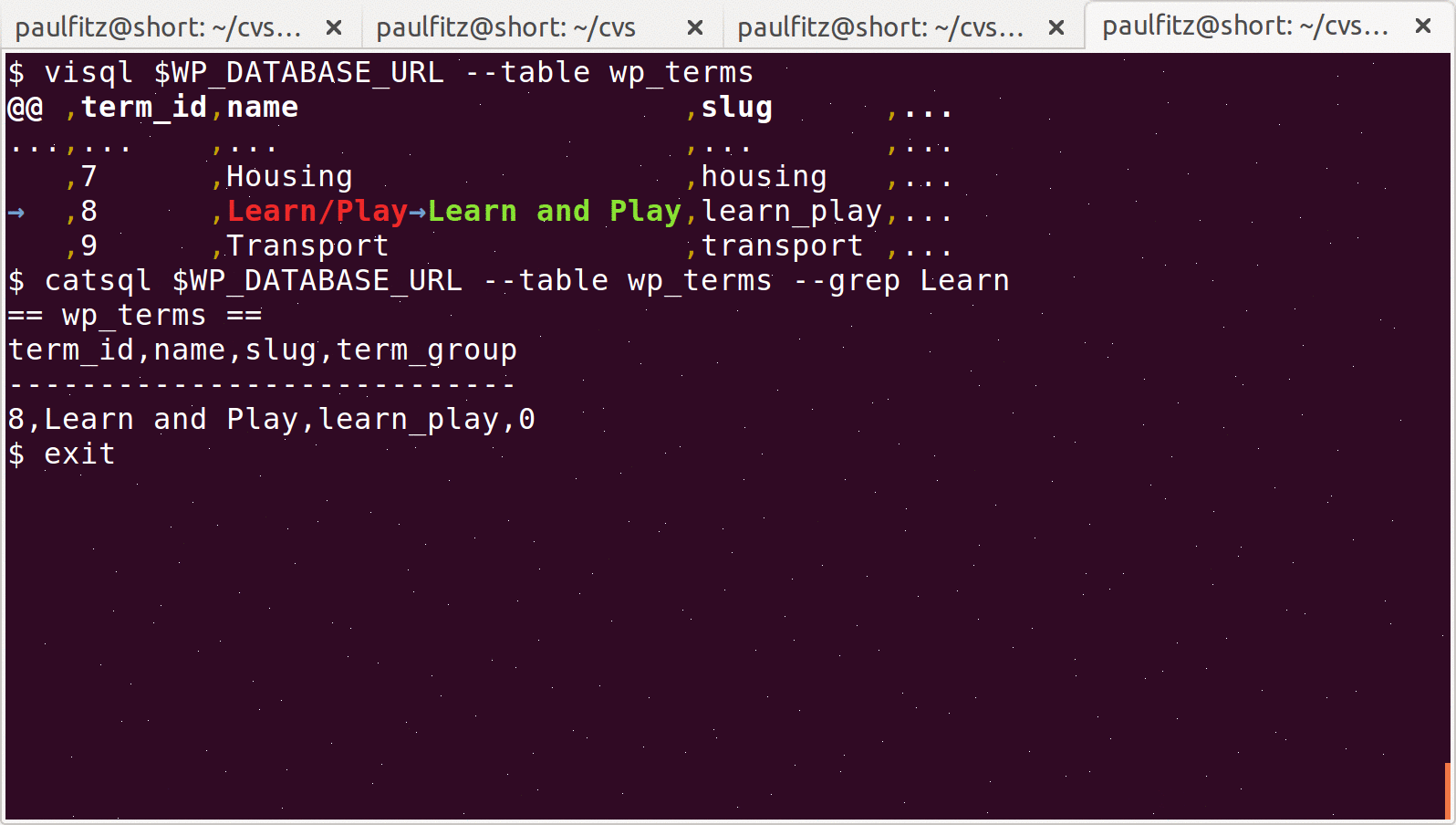
Here’s an example of PSV in action. I’m editing a PSV file called
checklist.psv that lists my current goals in life. I’m using emacs
to edit the file, and git to view differences against a previous
version.
I’ve configured git here to use daff
to view tabular differences cleanly. I’m doing this on my phone because phones
currently excel at showing emoji – the same thing on a laptop also works fine
but the poop is less cheerful looking.
One danger with PSV is that people could get sloppy about quoting
rules. With CSV, you’ve a good chance of seeing a comma in your data,
so you deal with quoting sooner rather than later to disambiguate that.
The business data I’ve seen in CSV form has never had 💩 in it,
so I could imagine someone skimping on quoting. One solution for that
is for more of us to put poop in our names and transactions,
Little Bobby Tables style (xkcd,
@mopman’s company).
There aren’t a lot of programs supporting PSV yet. So far as I know,
daff is the first.
The purpose of daff is making tabular diffs and helping with
version control of data, but until format converters crop up you
can use it to convert to and from psv as follows:
Every programming language is a special snowflake with its own
idiosyncratic beauty. Porting code from one language to another
is an art, requiring dodging and weaving to give idiomatic results.
If a library you’d like to use hasn’t been ported to your language,
one option is to use a foreign function interface (FFI).
A lot of reference implementations get written in C for this reason.
The result is definitely not a thing of beauty, but it works.
Haxe gives another option to a library writer who needs to support
communities using different languages. We can write the bulk of the
library in Haxe, have that automatically transpiled to the languages
we care about, and maybe add a little hand-written code in each
language to make the API feel comfortable. This scales the effort
involved way down.
For example, I wrote the daff library
in Haxe and publish it to:
It turns out that a bunch of PHP users showed up, giving great feedback.
That’s the target I personally know least about and would never have
gotten around to supporting without Haxe.
The Ruby language was the one I personally cared most about at the time
I started this. Ruby isn’t supported by Haxe, but it turns out
to be surprisingly easy to add a target to Haxe that is “good enough”
at least to translate code that is just a bunch of logic and algorithms
(I did this for ruby here).
There’s an important downside to this approach though: you may not get
as many pull requests. Users are not likely to be familiar with Haxe
(yet), so working with the source will be a challenge for them.
Haxe is a very straightforward, “common denominator” language
to read and write – but it is a new language.
The icon my RSS client uses is of a newspaper printed on
paper. RSS, RSS client, newspaper - that counts for three ways right there.
My t-shirts say nothing witty. I’m currently wearing one
emblazoned with an enigmatic logo for a local bike/walk event and
more importantly (if typography is any guide) THE LOGOS AND NAMES OF
ALL ITS SPONSORS. There’s a white stain from some goop my
daughter spilled on me that I half-heartedly and ineffectually tried
to rub off with my nails. Update: I changed t-shirt.
My laptop has no funky stickers from events or projects.
All there is, is a fading Intel Centrino Inside sticker it came with,
that has been gradually
rotating under my hand. It is now at a 30 degree angle, with traces
of exposed glue on the upper side. I don’t plan to take any action about
this anytime soon. Update: the sticker fell off.
I don’t have an interesting phone. My phone is as dumb as they
come, and not in a hip way, more in a total-neglect and out-of-touchy
kind of way. 2016 Update: gave in, now editing this in emacs
on an new phone so I don’t even have the retro thing going for me
any more. argh how do i type ctrl x ctrl s oh right volume down.
I’ve never changed my name on twitter. Why are people doing that? Update: I get this now, thanks to pikesleyUpdate: I mean Only Zuul Update: I mean Galactus of the LeftBIG PIPESNun Of The AboveTaylor's WiftHuman BlockchainUnicode BatmanLord of the FluesHead of Snorkelling6MillionBitcoinManSharing EconomistLol CreamPeter GunnJolly Local SwagmanDandy HighwaymanCubic's RubeCyber with RosieCyber with RoadiesInstitute of CodeineSantos L. HalperHugh Jif TrueBill ClayJeremy Kylo RenNew Year's SteveTriangle ManCognitive SourpussManic Bitcoin MinerNull of KintyreSafety ThirdPhineas GageThousand-yard StairsLondon Supercloudregister.registerWinstonNilesRumfoordSabre WulfCable SelectISA BusSides of MarchClick DummyFatuous PauperRinglefinchAlonzo MoselyIan BothanR DweenoHorse it's JuneWhen Devs CryRoko's ObeliskRiemann's ZeroPenn Rose-TileBelouis NoneRush Goalie2-Tractor AuthAll Is AflameJason Bourne ShellSCSI Terminator XbonsaikittenKid CharlemagneFronk-en-shteenMetric MartyrBilly Yum-Yum 2x2Full-Sack DeveloperKonix SpeedkingMetropolitan LiberalGlidd of GloodSexy Cartoon FoxElite: LiberalActivist GrudgeGee SusweptBig Dope ShillBritain’s Best TreeRogue NunDeus X-WingIce-Cream FanMan of LeisureSCMODSR DweenoAlternative FaxAuntie KitheraStraight Bananaiso8601 or GTFOFake GnusTwo 9s UptimeVex Machinaseveral peopleProof of KraftwerkUNNECESSARY HASHTAGSMutant TycoonLXC SaleSeb O'TeurSpinach RecallBactrian YAMLBig Daddy SmallsRoy NearyFreeze PeachStanky BeanSpecial Order 937HTTP RANGE 14Monk and beefheadChareth CutestoryMe an intellectual🇫🇷 is 🥓🇫🇷 is 🥓 🔷Content NegotiatorGallant and GoofuthBuddhachainHarlan PepperKid CharlemagneHeated Gaming MomentChuckie EggStalked by FitzyBanana Force KaleBan Anna Force KaleCoughin' NailSugar BearMC Ren & StimpyPrefab DoubtGraham SnumberPDF;dr1 like = 1 respect31 for 2Brian Force PlusBlue StratosHans GruberTulipCoinNo Bitcoin only ZuulSnoke is Jar-JarCore StickwitApplication JasonVoodoo Cray-1Onceable SpoonBall is in parking lotEmotional Support PeacockCheddar GeorgeGeorge BrontosorosGraham SnumberUVB 76Paywall FadeFerretocracyTauntaun ClubHan shot firstZoe Trope12-inch Dance MixPaperclip MinimizerDelete You're A CountBall TampererSatoshi StationAgnes DiPestoLeft-Wing Rabble RouserAmbitions not TargetsBolshevik Bin ManBitcoin BinmanDot Matrix with Stereo SoundClinical PsychologistCorridor of Uncertainty PrincipleGitHub for WorkgroupsTomato FarmerJewels RemainGareth's WaistcoatSelf-made Rent-a-LeftyDaze of Fuchsia ParsedThe Third Summers BrotherM'Kraan CrystalGerald of GalactusCommit BitShort LeaderEMF CamperTechno-Organic VirusNose For R2Countless Screaming ArgonautsMaribou StacyPariah CareyTrente PercenterFink AngelBette Davisize2-Bar PhraseTerry Jen-MistDon NewkirkMule With A Spinning-WheelNATHAN WIND as COCHESEContempt of Parliament/FunkadelicHot Dog Jumping Frog AlbuquerqueC. Bourne-FraitCorvus GlaiveBolivar TraskFormer user (Inactive)John Cougar MelonfarmIce Hockey HairNICAM StereoMany BothansDaryl CanvasObvious Exemptions For FishingThe π ApproximatornineteencharactersPeter HitchensBoycott NPMSbeve RogersInvisible Bordera² + b² = c²Pharell HoggPearsquoosher200 OK BOOMERJeff Porcaro fan accountPUT Maloneegg on branch5G REZOTONE SHIELDImpatient ZeroGrudge UnitSocial Distance WarriorLove In A Time Of CovidNerd ImmunityStaying In For The SummerHappy MaundysThe Longest Good FridayGuns don't kill people Tories doCovid Rules Everything Around MeMars Bar PaywallUnbeaten Covid Quiz ParticipantSome sort of database in the skyEdison's Boyhood GiftshopJoin A Union TodaySevere Childcare IssuesThe Rules Are OptionalGuns Don't Kill People Tories DoJoin A Union TodayGil O'TeenHarold Hill of Harold HillDid I learn nothing from Richie Aprile?PUT ON THE F***ING MASKWilliam Butler Yeets:(){ :|: & };:Sneedle FlipsockMute Ant Al Go RhythmWakanda ForeverJen d'RevealTechnical Co-FlounderMo SizelySenior Mouse Pushercopy of_copy of COVID (1).Oct20.xls(1) FINAL..xlsTier-2 of a ClownTier-1++Hello John Got A New Motor?Sabre Wulf16 CzechoslovakiansFreeman Hardy & Willis On The LandThe Dukes of Hazzard in the ClassroomI was brainwashedFeigning Concern For Fishermen .
The things I’m putting on this list and not putting on it
no doubt reveal assumptions I’m making about what is hip
that confirm further my squaritude in ways I can’t even imagine.
I totally get grumpy about the dumb things that kids are doing
these days.
I totally get grumpy about how much sense
the dumb things that kids are doing these days ends up making in the end.
Sometimes, you want to version-control your data.
As a programmer, many of us are used to putting everything in git.
For large datasets, that is currently a recipe for sadness, but
smaller ones can work just fine.
There are a few hurdles. CSV files have a special tabular structure
that git knows nothing about. This means that diffs will be noisier
than they need be, and that git may see conflicts when merging where
there are none.
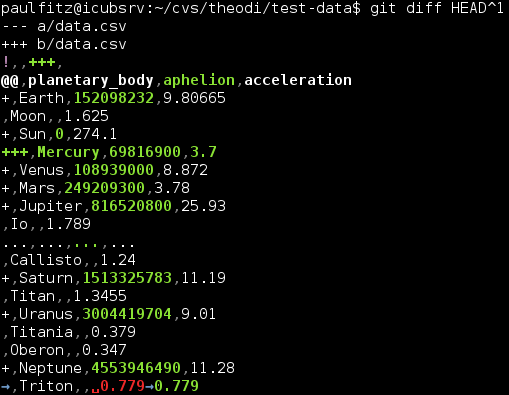
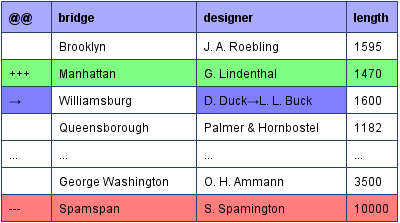
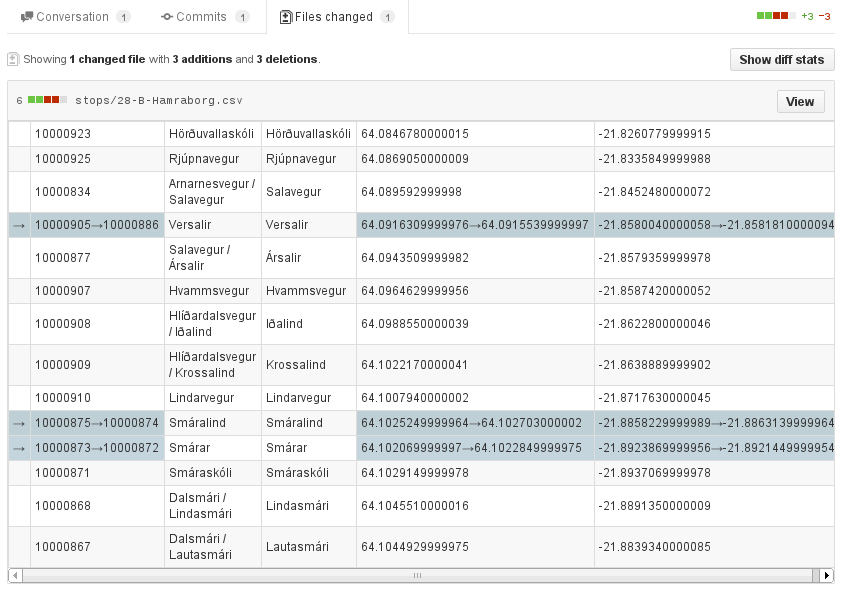
For diffs, James Smith has a great explanation and a good start at a solution. In the git client,
he proposes a custom git diff driver that understands CSV structure.
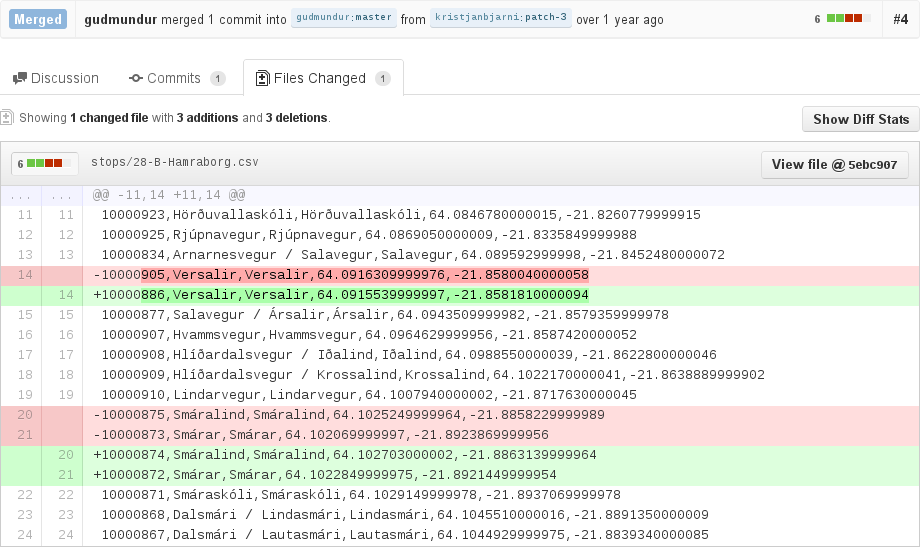
On the server side, he shows how to tweak gitlab or (via a plugin called CSVHub) github to get pretty diffs using the daff library.
For merges, on the client side, the coopy library has
for some time provided a similar merge driver to let git understand and use CSV structure. As of today,
daff can do the same, and it is much easier to install.
$ npm install daff -g
$ daff git csv
Once that is installed, you’ll get nice diffs produced by the same
library James used for his github plugin:
And you’ll get nice merges too. Let’s look at an example.
Suppose we have this table stored in digi.csv:
NAME,DIGIT
one,1
two,2
thre,33
four,4
five,5
And in one branch we correct thre to three,
and in another branch we correct 33 to 3:
Many years ago, I had a list of hobby projects I worked on from time
to time, each with a little summary that began:
“Until Google solves this problem nicely, …”
Most of these problems have now been solved, except this one:
I’d like to be able to communicate with aliens over great distances. Until Google solves this problem nicely, I’m working on a cosmic OS.
So Google hasn’t yet sorted this out, but Hans Freudenthal made a great start back in 1960 with Lincos, a “Language for Cosmic Intercourse.” Lincos starts out in a by-now conventional way (though it was inventing the conventions) with 35 pages describing a message for teaching basic math from first principles. Then it moves on to 12 pages on time. Then (and this is where things get very interesting) a whopping 79 pages on behavior, with imaginary conversations between imaginary personalities called Ha and Hb.
Ha and Hb discuss mathematics, since that’s about the only topic
for conversation, but that is arbitrary. In their discussions, they
introduce useful ideas such as good and bad (in the sense of
constructive versus non-constructive). Now we are getting somewhere.
I was struck by the value Freudenthal was able to get from
descriptions of extremely basic conversations, and wondered,
what could we communicate through richer interactions?
What if we described simulated environments that could actually
be evaluated, and played forward or reversed, to see full
simulated encounters take place? That was the seed for
CosmicOS.
The idea with CosmicOS is to start with math, as Freudenthal did,
and then build from there to a basic programming language,
and then from there to programs and simulations.
CosmicOS compiles down to a series of four arbitrary symbols
that could be encoded and transmitted any way we like:
In human-readable form, it looks kind of Lisp-y, since that
happened to be the syntax that introduced least complications.
CosmicOS is communicated as a long series of definitions and
demonstrations:
The initial language isn’t super important, because we
quickly bootstrap to any language we want. At the time
I was writing this part, I was keen on Java, so I wrote
a translator for it, targeting
what has to be the least efficient JVM ever written.
Then I wrote a little maze game in Java, shoved it in
the message, and promptly dropped the whole project
for several years :-). But now I’m back and fiddling
with it again, mostly at my son’s goading. I’ve
brought the project up-to-date enough to be able to
get pull requests.
You should contribute! You know you want to.
And just so its clear: I don’t have any particular belief in
extraterrestrials or any special reason to be interested in
contacting them. It is an interesting puzzle though, figuring
out all the different ways we might try to do so. You may also want to check out the recent
Archaeology, Anthropology, and Interstellar Communication book.
The Data Commons Co-op is a quirky start-up
that I’ve been helping out with. Its job is to
maximize the impact of the data held by its members, and reduce costs
in managing it. Its members are “alternative economy” organizations
of all types. Dan Nordley calls it “perhaps the geekiest of all cooperative
organizations on the planet!”
The infrastructure for collaborative data projects could be a
lot more fun than it is now.
Open Data initiatives are pushing things forward quite a
bit, primarily with government data in mind. That is sort of a
top-down direction of data flow. We’re looking at bottom-up,
grass-roots economic organizing. Worker co-ops, buying clubs,
community gardens, time banks, and so on. There’s a lot of
overlap in communities, and potential for network effects.
The Data Commons Co-op is a way to pay for the infrastructure that
every one needs and no-one can make happen alone.
So far we’ve produced a
simple diff format for tables documented on the Data Protocols site (some background in an Open Knowledge Labs post),
along with two programs called daff and
coopy for comparing and merging
table versions. Beyond the technology, we’re also figuring out
how to a culture of sharing can work in the economy. There’s
a lot of reflexive data-hoarding and hiding that goes on, which is
totally understandable. For individual organizations, the cost
of thinking about all the issues around sharing data can outweigh
by far any potential benefit. Hopefully the DCC can tilt that
equation!
I wrote daff to
better visualize diffs between tables (daff = data diff).
You don’t need this if you work with
append-only data, for example a stream of events
churned out by a sensor or bureaucracy. But if you
have a collection of assertions that can change with time
or need correcting, then data diffs are handy.
daff can be used from that command line,
as a library,
or on github, using James Smith’s CSVHub. CSVHub can convert a
diff like this: